
AdventureWorksCI Step 1 planning
This is part of a series on how to take the Adventureworks database and bring it inline with modern standards. How do we put a legacy SQL Server database into source control? What issues do we face and how hard is it? Then how do we build a continuous integration pipeline and possibly move towards continuous deployment. This series takes a look at how we achieve this whilst also implementing some coding standards and making an imperfect database a little bit better.
See the introduction: https://the.agilesql.club/Blog/Ed-Elliott/A-reference-for-creating-a-con…
Planning? Boreoff!
It might sound pretty dull but it is important that we understand firstly what it is we actually want to achieve and what the business value is of it.
Firstly, if you do not know what you want to achieve, how will you know when you are done?
Secondly, there is no point investing time and money on something that we will not see any return on.
The reason we plan is to work out if we should do it, how we can deliver real value at every step and to have a good idea that what we want is achievable within whatever constraints we are working to.
So lets plan
The first step is to take stock of why we are doing this? What is wrong with the current database:
- There are no tests -so- it is hard to make changes without knowing if you have broken something
- Deployments are manual -so- it takes a long time to generate the changes and they often miss something
- The code is inconsistent, different developers have their own style -so- it is hard to understand code unless you know the persons style
- The development databases are restores from production so contain sensitive data -so- we are at serious risk of a data breach / loss of customer trust / regulatory fines
- Developers overwrite each others changes -so- releases cause regressions which can mean we lose code so have to re-write things we have already written
- There is lots of unused code and commented out code -so- it makes it hard to maintain the code, sometimes you spend hours debugging only to find out that the portion of code you are looking in a ten thousand line procedure isn’t even being hit
I do not know about you but this sounds like pretty much every legacy database I have ever worked on!
The second step is to work out what it is we will do, it is often good to draw this out on a whiteboard to make sure that you are not missing anything.
So this is the dream team, we would like:
- To use git to store our source code -which- will stop developers overwriting each others code, let us clear out the old unused code and make changes knowing we can go back and see what happened if things go wrong
- To use SSDT to write our code -which- will allow us to find unused code, improve the code using refactoring and create automatic deployment scripts
- Use powershell to deploy changes to a local instance and run all tests -which- will give us confidence in our automatic deployments and help make sure we do not break anything else
- Use tSQLt to write unit tests -which- will mean we can start to make more rapid changes and also spend less time debugging
- Use Visual Studio Online to manage the work -which- means we can plan and estimate the work and decide what order we do things and how much time we should invest in this project
- Use Visual Sudio Online as a continuous integration server -which- means we can validate code on checkin and eventually also run rules to validate that our coding standards are being met
- Use Visual Studio Online to generate deployment scripts for other environments -which- means we do not have to manually build scripts and are always ready to deploy working code
There is more we could do such as using tools like octopus deploy to do the actual deployments but we have enough to be getting on with. The thing we should bear in mind is that we should use off the shelf tools, where we deviate from that we risk problems further down the line. For instance if we decided to use rexx (remeber that??) to write all our scripts we would have an additional dependency everywhere which we may not neessarily want.
Estimate
So now we know roughly what we want to do, we should estimate the work. This sort of work is something that should ideally be done in two work streams. First there is the upfront work to get the basics in place and then there is ongoing work to improve the process, we don’t know what the ongoing work will be otherwise we would just do it upfront so just bear in mind that it doesn’t have to be 100% perfect as long as you make sure you invest the time further down the line to improve the process when it needs it. Instead of just thinking about continuously integrating your work, think of it as continual improvement and the continual never stops.
I personally like to include user stories and tasks for the work on the ci process, sure it isn’t something you can sell to customers but whatever software you are writing has a business value and improving the quality and fixing the things that are wrong with it does have a business benefit.
To track the work I am going to use Visual Studio online, you should hopefully already have a system for managing and prioritising work. If you don’t then you should get one even if you are a single developer having a place to put things that need doing and to track your progess is vital to being organised and getting things done.
I have taken the requirements and built user stories for each, created tasks for each user story and assigned time estimates to each one:
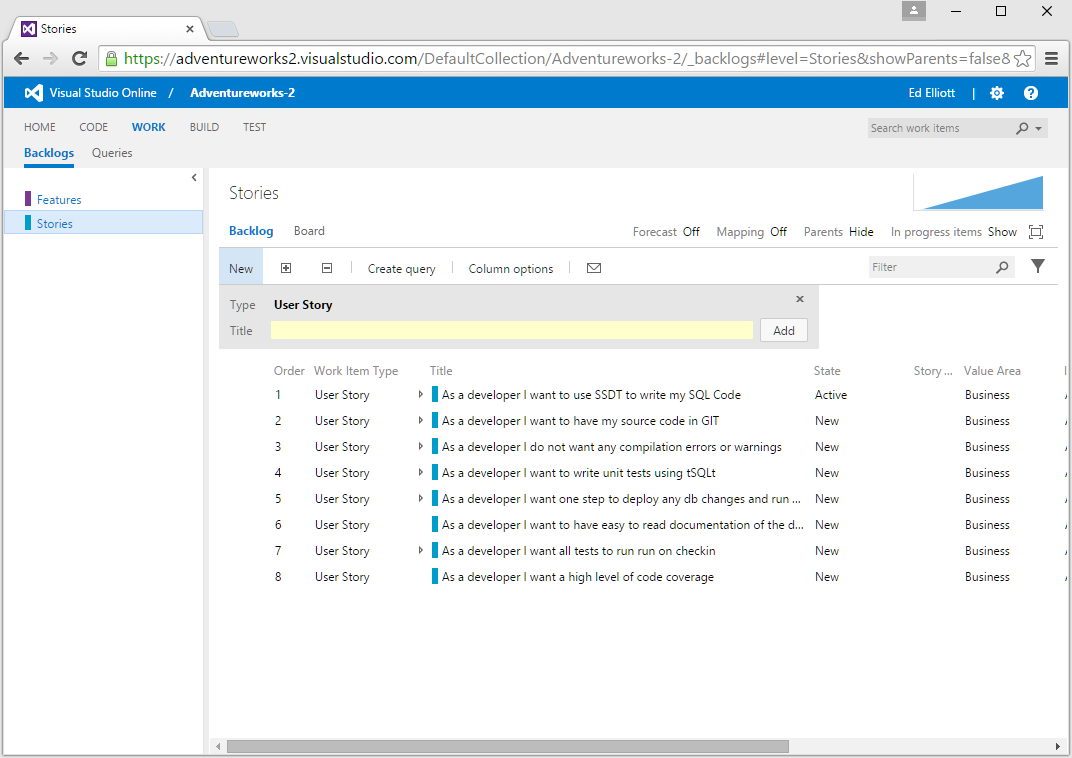
Using this I have an indication of how long each task will take and I also have somewhere I can relate each checkin back to. It is really easy in development to go off on a tangent fixing and changing all sorts of things so I like to tie each checkin with a task in the current sprint, if it isn’t related to a task then you have to really ask yourself whether you should be doing it. This doesn’t mean that you shouldn’t refactor, certainly as you work with the code you should always aim to make it a little bit better than it was before, rather that should be in conjunction with the other work you are doing.
Now we have the estimates and we should be able to pretty easily see the dependencies we can choose what we will do upfront and what we will do later. Perhaps the amount of work feels to much to do initially so to start with we will get the code in SSDT or perhaps start using tSQLt. Each project and organisation is unique so do whatever works for you but have a plan of where you want to get to and start heading in that direction.
In the next post we will be creating an SSDT project and getting the Adventureworks code out of the database and into the file system where code should be stored!
Comments:
Shaunt Kojabashian
June 17, 2015 - 05:47
great idea
just wanted to say this is an awesome idea. I don’t have a ton of free time but I’d love to help out some. I’m a newbie to ssdt and tsqlt but I’d love to help.
Ed Elliott
June 17, 2015 - 06:37
Thank you, I will get it into
Thank you, I will get it into source control in the next post and push it to github and would welcome all and any contributions - if you also wanted to write a blog post I would be happy to link to it.
I think that the more people who help the better it would be!
Ed
Tiago
January 28, 2017 - 16:54
Hi Elliott, Just want to
Hi Elliott, Just want to congratulate you for your fantastic amazing work on this blog. I’m a DBA in London that has been suffering too much with manual deployments. I’m a complete novice to the CI and CD pipeline and after trying the Redgate DML Automation tool + teamcity + octupus deploy with a lot of success but with a Redgate license cost that my employer cannot support I decided to research what was around and I found your blog. I’m completely stuck to it and I really appreciate your mission here. What you said about companies not using source control+testing+ci+cd is very true and I really think things need to change. Once again, thanks a lot for your time and I will be a frequent reader from now on.
Cheers!
Ed Elliott
February 10, 2017 - 16:10
Great! If you need a hand
Great! If you need a hand with anything feel free to ping me :)