
AdventureworksCI Step 3 Handling data with SSDT
This is part of a series on how to take the Adventureworks database and bring it in line with modern standards. How do we put a legacy SQL Server database into source control? What issues do we face and how hard is it? Then how do we build a continuous integration pipeline and possibly move towards continuous deployment. This series takes a look at how we achieve this whilst also implementing some coding standards and making an imperfect database a little bit better.
See the introduction: https://the.agilesql.club/Blog/Ed-Elliott/A-reference-for-creating-a-con…
There is an elephant in the room and he is asking what to do about static data
SSDT is great, really great at working with schema objects such as stored procedures, tables, functions etc but there isn’t any in-built capability to handle static data that is needed to support a database.

What is static data?
Just to be clear we are not talking about the actual data that is the whole raison d’etre of a database, instead we are talking about the reference data, static data, lookup data - whatever you want to call it, the data that enforces referential integrity:
create table customer_type
(
customer_type_id int not null,
customer_type_description varchar(32) not null,
constraint [pk_customer_type] primary key clustered (customer_type_id)
);
which is referenced by:
create table customer
(
customer_id int identity(1,1) not null,
customer_type_id int not null,
constraint [fk_customer__customer_type] foreign key (customer_type_id) references customer_type(customer_type_id)
)
The data in the customer table should be backed up and managed using your backup/restore policies, it is what some people call the useful part whereas the static data should be part of source control and deployable!
Where does static data come from?
There are two main sources of static data, the first is the database itself. Often when defining static data someone has a description and the application makes all requests using that description, internally the database code takes the description, looks up the id and uses that from then on - here is a classic example:
create procedure get_customers_by_type( @customer_type varchar(32))
as
declare @customer_type_id int;
select @customer_type_id = customer_type_id from customer_type where customer_type_description = @customer_type;if @customer_type_id is null
return;select customer_id from customer where customer_type_id = @customer_type_id;
In cases like this where only the database needs to know the id it is common to define the column as an identity and use those values.
The other source is when id’s are used by applications for example in C#:
public enum customer_type {
…
}
In this case the database could still keep its own internal references and translate them when making calls and creating responses or the applications and databases can standardize on the id. The benefit of using the same id / value pair everywhere is that a value is always the same id no matter where you see it which cannot be overvalued.
I am not quite sure why but for some reason databases that use this sort of system still sometimes declare the id columns with identity making identity inserts necessary when setting up your data but that is a winge for another day.
So how do you manage this in SSDT?
SSDT manages objects like tables and stored procedures very well but doesn’t do much with data so we are on our own a little bit. The good thing about SSDT is that there is the flexibility to do other “stuff” in that we get a pre and a post deployment script which we can put in any T-SQL we like.
My suggested route to managing your static data in SSDT is to put it into a post deployment script.
Idemposomethingorother
When you deploy an SSDT project the pre and or post deploy scripts are run everytime so you need to ensure they are re-runnable or idempotent. To do this, by far the easiest and I personally believe the most elegent is to use merge statements to ensure your static data tables are always correct.
If you do not want to use or cannot use merge statements ( < SQL 2005 ) then the second best is to have insert statements that join against the live table and only insert missing rows. When you need to change a value rather than insert it then you can just do an update against the old and new values to keep it current.
Whatever you do make the scripts re-runnable as if you set this all up correctly they will run lots (actually a few more times than lots).
How do I do that? I have like 100 tables to get data from and I can’t write merge statements there is too much text and it makes me go blind
OK the first step, whichever approach you take merge or re-runnable inserts etc is to create a post deployment script, just right click your project choose “Add” then “Script” and finally “Post-Deployment Script”. Note you can add more than one but only the last one added will have the Build action set to “PostDeploy”:
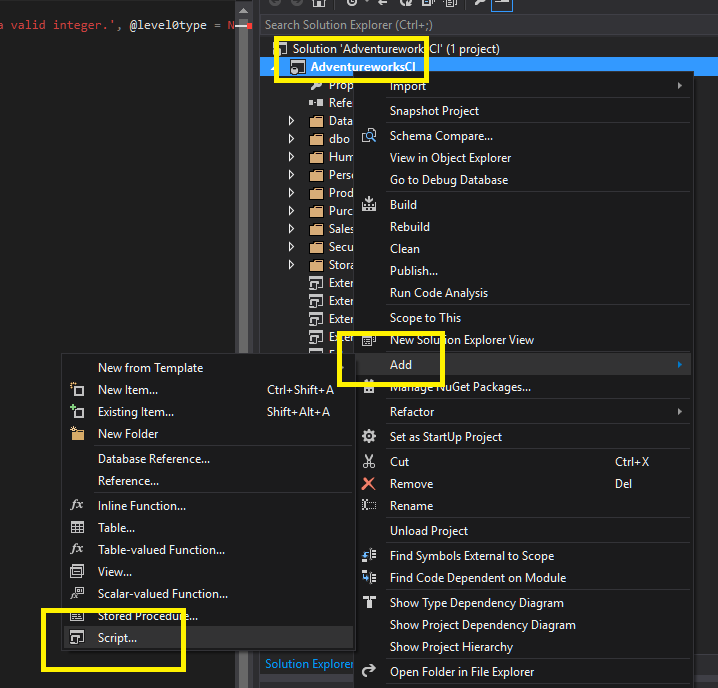
Now you have a post deploy script it will run after every deployment you do. If you generate a script rather than deploying via sqlpackage.exe then the post deploy script is tacked onto the end.
But I can’t write merge statements and certainly not for like a gazillion tables
Fear not my friend, you have a few options, you can:
-
Suck it up and become the world’s leading expert on writing merge statements
-
Use sp_generate_merge to generate merge statements which you can then copy into the post deploy script
-
Use my MergeUI to import tables from SQL Server into your project and manage the merge statements
You can get more details on sp_generate_merge from here.
You can get more details on MergeUI here.
Whatever approach you use, merge statements aren’t that hard to understand they are basically a combination (any combination you like) of a select, update, insert and delete in ont enormous sql statement. For a great overview see: http://www.purplefrogsystems.com/blog/2011/12/introduction-to-t-sql-merg…
Is it really that simple?
Yes.