
Looking at SSDT upgrade scripts
I have been using SSDT seriously for a couple of years now and have really been impressed with the code that is generated to upgrade schemas and over that time have learnt to trust that SSDT generates good upgrade scripts.
It is however a concern that a tool generates the deployment script rather than a person and to move to a continuous deployment environment we need to be sure that the tooling is better than a person. To be clear I am already in that camp but wanted to spend some time exploring what upgrade scripts get generated in which scenarios.
Scenario 1 - Making a column smaller
In this first example I will take an existing table and change one of the columns so that it is smaller we will go from:
create table employees(
id int not null primary key,
firstname varchar(max) not null
)
to:
create table employees(
id int not null primary key,
firstname varchar(1024) not null
)
The Result
In this example we get a table rebuild:
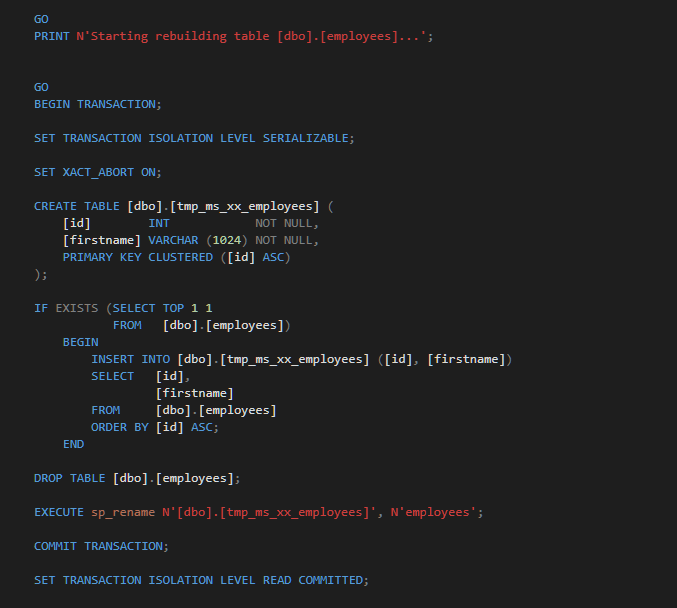
Scenario 2 - Changing a column from a varchar to an nvarchar
create table employees(
id int not null primary key,
firstname varchar(max) not null
)
to:
create table employees(
id int not null primary key,
firstname nvarchar(max) not null
)
The Result
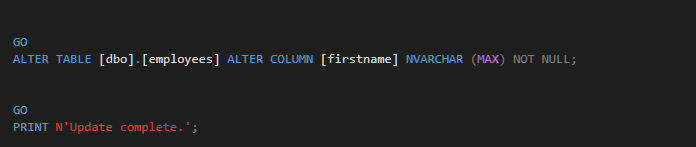
Scenario 3 - Changing Non-Null columns to Nullable
In the next scenario what happens when we remove a non-null constraint? I would like to see a alter table rather than a table rebuild:
create table employees(
id int not null primary key,
firstname varchar(max) not null
)
to:
create table employees(
id int not null primary key,
firstname varchar(max) null
)
The Results:
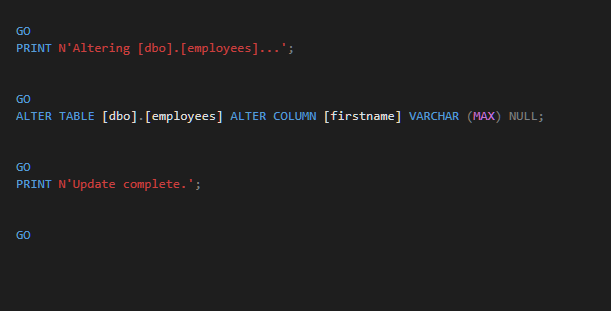
Scenario 4 - Add a non null column
This one is a little more interesting, what happens when we add a column with a constraint and no default value so if there is data in the table this should fail:
from:
create table employees(
id int not null primary key,
firstname varchar(max) not null
)
to:
create table employees(
id int not null primary key,
firstname varchar(max) not null
lastname varchar(200) not null
)
The Results:
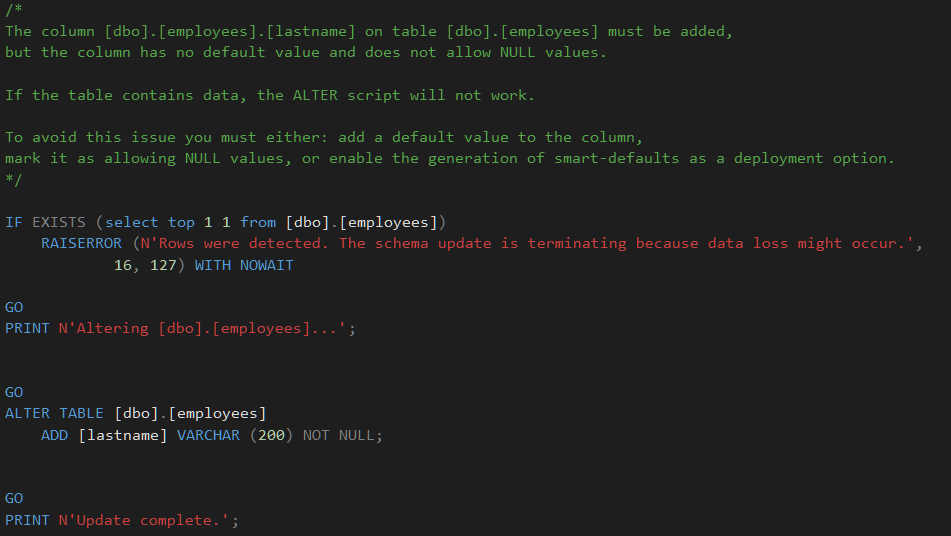
The interesting thing about this is firstly the script will stop if the table contains any data as the deploy would fail.
Secondly there is a comment that gives you multiple ways to fix it. NICE.
Scenario 5 - Add a null column
If we do the same thing but add a nullable column to the end of the table what do we get?
from:
create table employees(
id int not null primary key,
firstname varchar(max) not null
)
to:
create table employees(
id int not null primary key,
firstname varchar(max) not null
lastname varchar(200) null
)
The Results:

Done
I think that is enough for now, the generated code is basically what I would generate except that when adding scenario 5 I would have added it as a nullable column, then update the value and set to null after that but I can live with that.
I will likely re-visit this topic with some more interesting scenarios but that is enough for now :)
ed
Comments:
Anonymous
November 3, 2015 - 23:21
Another consideration - renaming a PK Constraint
I encounter this one far too often - in TSQL, you can issue an sp_rename command to rename a PK Constraint. When generated through SSDT, we get a complete table rebuild, even if we use a Refactor-Rename command to change the PK Constraint name. Admittedly, this doesn’t come up too often, but more often than I’d like when people leave out constraint names in their initial builds.
Ed Elliott
November 3, 2015 - 23:24
It seems odd that it isn’t
It seems odd that it isn’t dealt with by the refactoring support - why don’t you raise a connect item against it and see if it can be fixed?