
SSDT Migrating Data Without Losing It
You sometimes want to do things like split a table into two or move a column into another table and when you use SSDT or the compare / merge type of deployments it can be hard to migrate the data in a single deploy as you can’t insert the data into a table that doesn’t exist and you can’t drop the data before it has bee migrated. To fix this we can use pre/post deploy scripts in SSDT. The overall process is:
-
Pre-Deploy Script, check for column to be migrated
-
Save data in new table not in SSDT (you could have it in SSDT if you use it for multiple releases etc)
-
Let SSDT drop the column and create the new one - you will need to have the option set allow data loss on incremental deployments
-
In the post-deploy copy the data to the new table
To give a run through of this we want to get from this ERD:
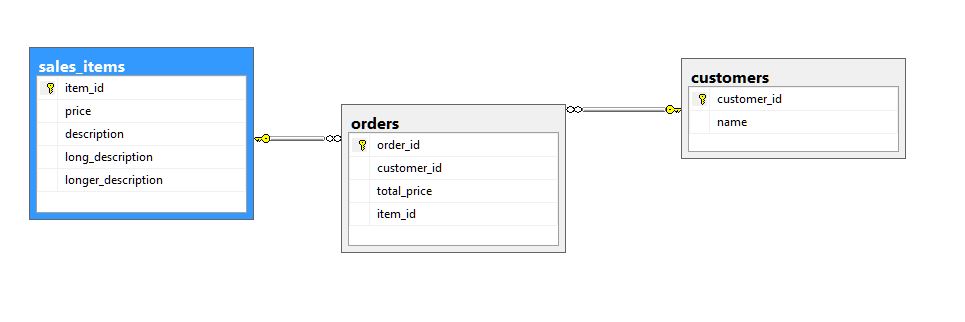
to this ERD:
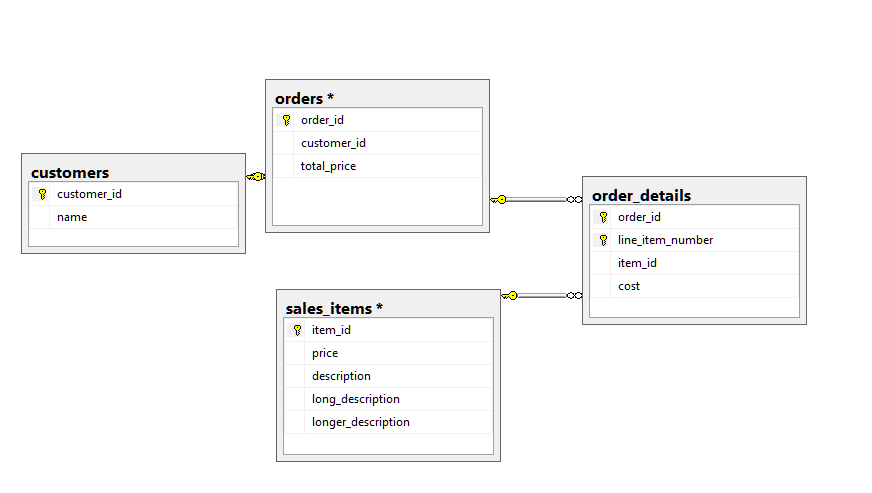
Basically we are moving from having a single line item per order number to a set of line items. So in SSDT we create our new table and delete the old column, then we add a pre-deploy script with:
https://github.com/GoEddie/SSDTDataMigrateDemo/blob/master/src/MigrateDe…
if exists(select * from sys.columns where name = 'item_id' and object_id = object_id('orders'))
begin
if object_id(‘order_details_migration’) is null
begin
create table order_details_migration
(
order_id int not null,
item_id int not null
);
end
insert into order_details_migration(order_id, item_id)
select o.order_id, o.item_id from orders o left outer join order_details_migration mig on o.order_id = mig.order_id where mig.order_id is null;
end;
If you want to play along at home, deploy this project:
https://github.com/GoEddie/SSDTDataMigrateDemo/tree/6a8ebf92c372461b93f0…
The version with the updated table and migration scripts is:
https://github.com/GoEddie/SSDTDataMigrateDemo/tree/cfc61fbcd61e0c110629…
The post deploy script would have:
https://github.com/GoEddie/SSDTDataMigrateDemo/blob/master/src/MigrateDe…
if object_id(‘order_details_migration’) is not null
begin
insert into order_details(order_id, item_id, cost, line_item_number)
select mig.order_id, mig.item_id, si.price, 1 from order_details_migration mig
inner join sales_items si on mig.item_id = si.item_id
left outer join order_details od on mig.order_id = od.order_id and mig.item_id = od.item_id
where od.order_id is null;
delete from order_details_migration where order_id in (select order_id from order_details);
end
You can run these scripts lots of times and they will only do anything when you have work to do so when you add them to your project add a jira ticket or whatever to take out the bits you don’t need from the pre-post deploy scripts at a later date - the order_details_migration table will be dropped on the next publish.
Anyway I hope this helps,
Enjoy
Ed
Comments:
Lance
January 19, 2016 - 20:47
Raise Error - Rows were detected
First off, great blog! I appreciate the time you have spent creating this content.
I’m currently implementing an SSDT process and I’m curious if you have settled on a pattern for data motion/migration (since this solution does not work if you are blocking on data loss). I’m currently wanting SSDT to drop foreign keys before running my pre-deploy scripts so that I could move all data to temp tables, then SSDT would not see any data loss, but I’m early in the research phase.
Any insight you could share would be appreciated.
Thanks in advance,
lk
Ed Elliott
January 19, 2016 - 23:05
Hi lk,
Hi lk,
Thanks for your comment about the blog!
If you modify the table referenced by a foreign key then SSDT will disable the key (NOCHECK) - you could write a deployment contributor that grabbed all the tables being updated in your pre/post deploy scripts and then disable before your pre-deploy script ran and re-enable after the post-deploy script - that would be pretty cool actually!
ed
Karel Frajták
July 7, 2016 - 15:12
Lots of data motion scripts
Hi ed,
nice article! How do you deal with lots of data motion scripts? Do you merge them in one script pre- and postdeployment scripts? Imagine project with lots of pre- and postdatamotion scripts (similar to the one in this post).
Thanks for your anwer,
Karel