
What is SSDT all about aka Why should I bother?
I often get asked the questions “What is SSDT" and I have wanted to have a single reference as to what it is as it is actually pretty big. To be clear I am just looking at the database projects version of SSDT what was originally SSDT rather than the BI tools that came with SSDT-BI and are now being merged with SSDT – Perhaps I will expand this to include those one day but probably not.
What I have done is created a picture of the parts of SSDT and I will write a little blurb and give one or more links to somewhere for further reading, I really hope that someone finds this useful as SSDT is a great tool that should be used by more SQL developers.
For me:
SSDT is a tool set that consists of:
- A development ui
- A deployment system
- A documented api
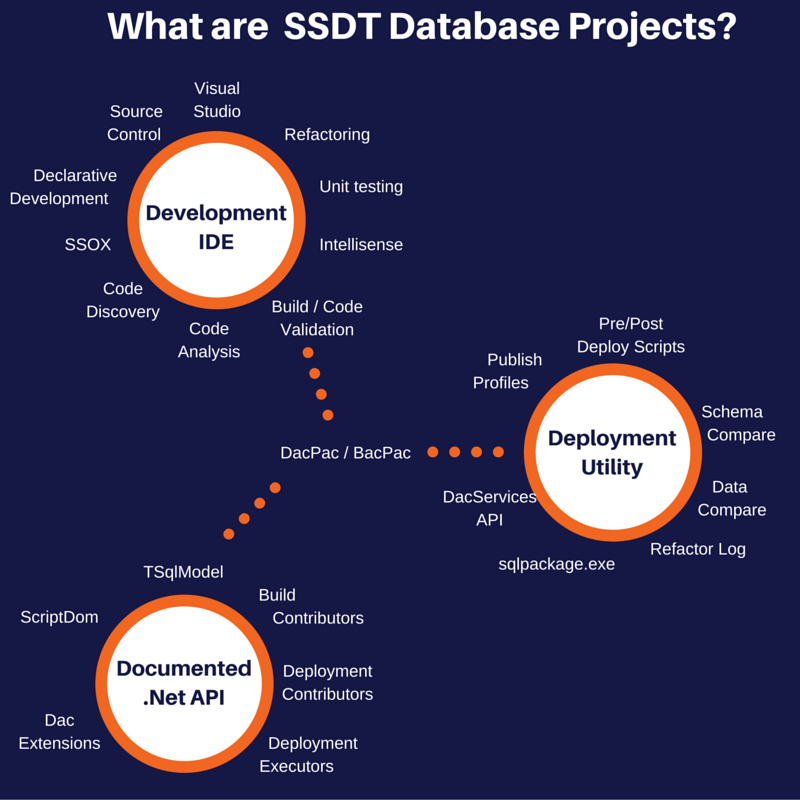
DacPac / BacPac:
The three major components in SSDT are linked together using dacpac’s and bacpac’s.
The dacpac and bacpac are either the output from SSDT projects or exported from live databases. The files themselves are zip files which use the Microsoft “Open Packaging Conventions". If you rename them to .zip you can extract them and see the contents. A dacpac contains the model which is enough information to be able to re-create both the DDL and DML of the database to be deployed. A bacpac contains the model but also contains data files with the table data in the BCP format. Having both the schema and the data means that not only the schema but also the data can be deployed.
“Dacpac braindump - What is a dacpac?"
http://sqlblog.com/blogs/jamie_thomson/archive/2014/01/18/dacpac-braindu…
Msdn: Data-tier Applications (see section “BACPAC")
https://msdn.microsoft.com/en-GB/library/ee210546.aspx#Anchor_4
Development IDE
The first major category that we can break SSDT down to is that it is a development IDE, it has tools and utilities to help us write code and that can’t be a bad thing.
Visual Studio
Visual Studio is a great UI, the editing capabilities are excellent (things like alt+shift selecting lines and changing multiple lines at the same time and tabbing lines across together). The best thing about it though is that it is extensible so you can use tools like resharper or the redgate sql prompt or even your own extensions.
In my case I use resharper and altought doing ctrl+n (with the resharper keyboard mappings) will not find t-sql objects it does find files so as long as you name each file the same as an object it is super easy to navigate around a project.
If you do not have a license for Visual Studio then you can use the free express version or the Visual Studio shell which is good but you can’t add extensions. If you are working on a community project or part of a smaller company then you can use Visual Studio Community edition which is the same as the Professional edition but is free.
Downloads | Visual Studio
https://www.visualstudio.com/en-us/downloads/download-visual-studio-vs.aspx
Source Control
You do not strictly have to use source control to use SSDT but you do need to get your DDL and DML into at least one text file and have that in the file system so you may as well use source control as you effectively get it for free.
When you create a project you can either start adding files manually or you can import from a database so taking a database and getting it under source control is really quite simple. If anyone is stuck doing this feel free to ping me, I am sure that I can help you :)
HOWTO Get T-SQL into SSDT
https://the.agilesql.club/Blogs/Ed-Elliott/HOWTO-Get-An-Existing-Schema-…
Declarative Development
The traditional way of writing code for SQL Server, either the underlying schema so tables and indexes or the code i.e. stored procedures and functions etc. is to take an existing database (even an empty one) and make incremental changes to it until it ends up how you want it. Even writing this sounds like a waste of time but I digress.
With SSDT you specify what you want and then let the tools take care of making that happen so if you have a table definition like:
create table knees_up_mother_brown(
knees_up_id int,
knees_up_date datetime
)
And you want to change the definition so that it looks like this:
create table knees_up_mother_brown(
knees_up_id int,
up_date datetime2,
down_due_date datetime2 null,
constraint [pk_knees_up_mother_brown] primary key (knees_up_id)
)
If you use SSDT and the declarative approach then your work is done, if you use the traditional approach then you need to work out how you want it to look like (done) and then the steps to go from the first version to the second.
Something like:
-
sp_rename on the knees_up_date column
-
find all the references to the old column and change them to the new one (hopefully there won’t be many ?
-
add the extra column down_due_date
-
add the primary key constraint
On top of this as well as storing this update script you need to make sure you still have the definition from which you changed to apply the script to. You should also make it idempotent so you only actually try to make the changes if they haven’t been run before. Alternatively use the declarative approach in SSDT and not worry about any of that.
Declarative Database Development with SSDT
This is a talk by Gert Drapers, he is the grandfather of SSDT, go listen to him tell you a bedtime story.
https://sqlbits.com/Sessions/Event10/Declarative_Database_Development_wi…
SSOX
The SSOX or SQL Server Object Explorer is a cool utility that lets you connect to a live database and do things to it like debug stored procedures or update individual objects. It also lets you see a view of you projects after all references have been resolved so if you use “Same Database" references you can see how your end project will end up – really useful.
Place Holder
There hasn’t been much written about the SSOX but it is really cool, go check it out. I have an article at Simple Talk that is waiting to be published, when that happens I will put the link here.
Code Discovery
What I mean by this is you can find code easily, you can right click on an object name be it a table or function or whatever and jump to the definition. You can also do the reverse you can right click on an object and find all the references. This reference discovery is really useful as you can get examples of how objects are used within the project and get an idea of how wide ranging a change to it would be.
No Link
Code Analysis
If you write a stored procedure that references a table that does not exist it lets you merily deploy it but in SSDT you will not be able to build the project. This is huge for SQL developers as it drastically reduces the risk of a typo causing a runtime error at a later date. The code analysis in SSDT ranges from validating that the syntax is correct for the specific version of SQL Server your project targets (on the properties page you can set the version) to validating that references to objects are correct as well as providing some analysis rules and a framework to let you create your own rules.
Creating your own rules is really quite simple and imagine as a DBA creating a rule for your developers which dis-allowed or flagged certain things (scalar functions, cursors, non-sargable searches that could be made sargable pretty simply) that would be a great thing to do. I know that if I was still a DBA I would be basically insisting that developers writing code for databases I could get called out for at night used SSDT and there were some pretty robust code analysis rules in place :)
Walkthrough Authoring a Custom Static Code Analysis Rule Assembly for SQL Server
https://msdn.microsoft.com/en-us/library/dn632175.aspx
Enforcing T-SQL quality with SSDT Analysis Extensions
https://the.agilesql.club/Blogs/Ed-Elliott/Enforcing-TSQL-Code-Quality-T…
Refactoring
This, for me, is the killer feature of SSDT – consider the normal approach to compare / merge deployments when you want to rename a table. If you rename a_table to a_cool_table when you go to do the compare the tool will say:
- Create new table a_cool_table
- Drop table a_table
Dropping the table is really bad as it means you need to write some custom code to handle it. In SSDT if you use the built-in refactoring support to rename or move an object to a different schema it will not
only find all the references to your object and update them but it will also create an entry in the refactor log (more on that later) which will cause a sp_rename to be generated rather than a drop and create. I know right, awesome :)
How to: Use Rename and Refactoring to Make Changes to your Database Objects
https://msdn.microsoft.com/en-us/library/hh272704(v=vs.103).aspx
I also have an article coming out on simple talk about this so I will add the link when it is published.
Unit Testing
If you write code you should unit test, ok? There are a few approaches to unit testing in SSDT, if you like using tSQLt then you can simply include it in the project (I include it as a reference in a dacpac
see https://the.agilesql.club/Blog/Ed-Elliott/AdventureWorksCI-Step5-Adding-…).
SSDT however comes with it’s own test framework which lets you write unit tests in VB.Net or C# - the tests run T-SQL and there are pre/post scripts you can run so if you can do it in SQL Server you can test it using this.
Getting Started with SQL Server Database Unit Testing in SSDT
http://blogs.msdn.com/b/SSDT/archive/2012/12/07/getting-started-with-sql…
Intellisense
We shouldn’t really have to have this discussion but if you are developing without intellisense then you may as well develop in notepad – you can do it but it is not efficient so don’t do it.
SSDT comes with a great version of intellisense that makes development faster and easier – a real no brainer here. I realise that the redgate sql prompt and ssms also include intellisense but this isn’t a comparison it is just telling you what SSDT is all about :)
No Link
Intellisense completes words etc what do you want to know more than that?
Build / Code Validation
This is where SSDT really gets interesting, instead of a disparate set of tables and procedures each doing their own thing and possibly generating runtime errors you cannot build an SSDT project with invalid code.
The example I always give is of the stored procedure that runs at the end of each year which relies on a table that has been modified, the traditional method of writing T-SQL does not stop breaking changes and because not many SQL developers write unit or integration tests it is unlikely that any issues would be found until the critical year end.
If you have an error in the SSDT project the project won’t build – so you must fix it before you can move on. If you project does build then it creates a dacpac which is effectively the binary output format that can be used to deploy changes to actual databases.
No Link
I couldn’t find anything that talks about the SSDT build and verification process – if anyone has a link let me know and I will update it or maybe write something myself.
Summary
That is it for part 1, in part 2 and 3 I will cover the deployment and api parts of SSDT. Any questions please shout and if anyone has some better links please feel free to send them to me and I will update this.
Finally if anyone thinks I am missing any major part of SSDT then shout and I will add it to the diagram :)
Comments:
Anonymous
January 12, 2016 - 16:04
SSDT - Why Should I Bother
Very informative. Normally I just stay in SSMS. I really need to look into SSDT.
Ed Elliott
January 14, 2016 - 12:51
You really should :)
You really should :)
Darek
September 16, 2016 - 10:42
Problems with SSDT…
Yeah, SSDT is great… apart from the times when it’s not. I was developing a project for fraud detection and had two databases. One was doing the analysis on data and stored history, the other one was the live system. I had to reference objects in the live from the other. To decouple the two databases and put a layer of abstraction between them I used synonyms. What I learned the hard way was this. When you have a synonym defined with variables, sth like “create synonym syn.YourTable for [$(YourTargetDB)].[dbo].[YourTable],” everything is OK as long as you don’t use the object in an in-line table-valued function or a view. You can use this in a stored procedure and your project will compile. Use it in an iTVF and all bets are off. You won’t be able to compile, you won’t be able to make the errors go away (trust me on this) and in effect you won’t be able to publish. “Great” stuff, Microsoft. This problem has been there for months, if not years. Still not resolved.