
What is SSDT? Part 3 - an API for me, an API for you, an API for everyone!
In the final part of this 3 part series on what SSDT actually is I am going to talk about the documented API. What I mean by documented is that Microsoft have published the specification to it so that it is available to use rather than the documentation is particularly good - I warn you it isn’t great but there are some places to get some help and I will point them out to you.
The first parts are available:
https://the.agilesql.club/blogs/Ed-Elliott/2016-01-05/What-Is-SSDT-Why-S…
and
https://the.agilesql.club/blog/Ed-Elliott/2015-01-06/What-Is-SSDT-Part-2…
Same as before, i’ll give an overview and some links to more info if there are any :)
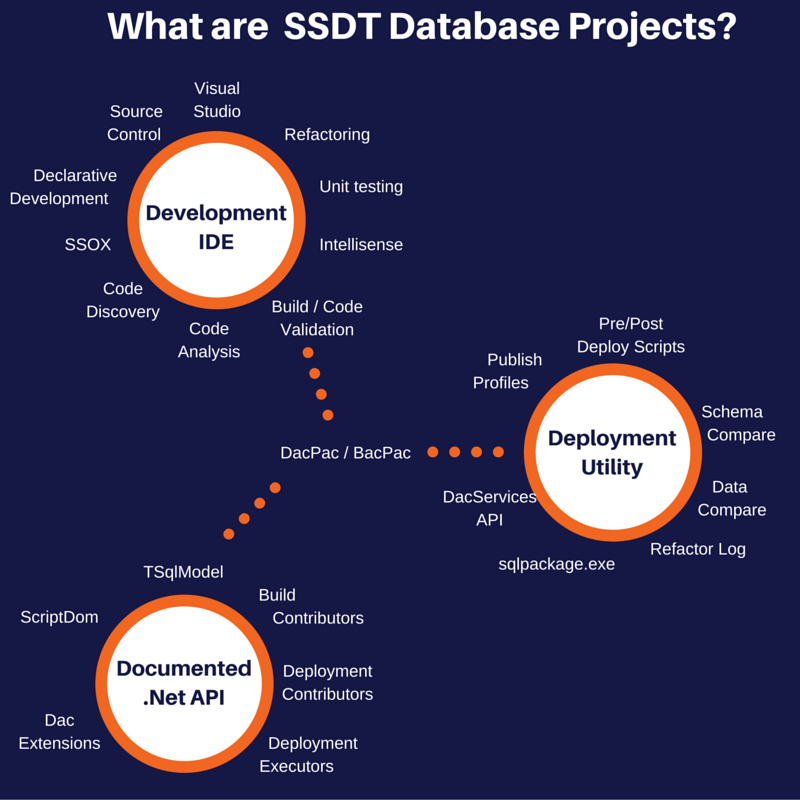
Documented API
There are a number of different API’s broadly split into two categories the DacFx and the ScriptDom. The DacFx consists of everything in the diagram around the API’s circle except the ScriptDom which is separate.
ScriptDom
For me SSDT really sets SQL Server apart from any other RDBMS and makes development so more professional. The main reason is the declarative approach (I realise this can be replicated to some extent) but also because of the API support - name me one other RDBMS or even NoSql system where you get an API to query and modify the language itself, go on think about it for a minute, still thinking?
The ScriptDom has two ways to use it, the first is to pass it some T-SQL (be it DDL or DML) and it will return a representation of the T-SQL in objects which you can examine and do things to.
The second way it can be used is to take objects and create T-SQL.
I know what you are thinking, why would I bother? It seems pretty pointless to me. Let me assure you that it is not pointless, the first time I used it for an actual issue was where I had a deployment script with about 70 tables in. For various reasons we couldn’t guarantee that the tables existed (some tables were moved into another database) the answer would have been to either split the tables into 2 files or manually wrap if exists around each table’s deploy script. Neither of these options were particularly appealing at the particular point in the project with the time we had to deliver.
What I ended up doing was using the ScriptDom to parse the file and for each statement, (some were merge statements, some straight inserts, some inserts using outer joins back to the original table and an in-memory table) retrieved the name of the table affected and then generating an if exists and begin / end around the table, I also produced a nice little excel document that showed what tables where there and what method was used to setup the data so we could prioritise splitting the statements up and moving them towards merge statements when we had more time.
Doing this manually would have technically been possible but there are so many things to consider when writing a parser it really is not a very reliable thing to do, just consider these different ways to do the same thing:
select 1 a;
select 1 a
select /*hi there*/ 1 a
select * from (select 1 one) a
select 1 as a;
select 1 as a
select /*hi there*/ 1 as a
select 1 as [a];
select 1 as [a]
select /*hi there*/ 1 as a
select * from (select 1 one) a
;with a as (select 1 a) select * from a
;with a as (select 1 as a) select * from a
;with a as (select 1 a) select * from a
;with a(a) as (select 1) select * from a
;with a(a) as (select 1 a) select * from a
select 1 a into #t; select a from #t; drop table #t;
select 1 a into #t; select a a from #t; drop table #t;
select 1 a into #t; select a as a from #t; drop table #t;
I literally got bored thinking of more variations but I am pretty sure I could think of at least 100 ways to get a result set with a single column called a and a single row with a value of 1. If you think that parsing T-SQL is something that is simple then you should give it a go as you will learn a lot (mostly that you should use an API to do it).
One thing that causes some confusion when using the ScriptDom is that to parse any T-SQL unless you just want a stream of tokens you need to use the visitor pattern and implement a class that inherits from TSqlFragmentVisitor - it is really simple to do and you can retrieve all the types of object that you like (CreateProcedure, AlterProcedure etc etc).
So if you have a need to parse T-SQL then use the ScriptDom, it is really simple what is not so simple is the other side of the coin, creating and modifying objects to create T-SQL.
If you need to do this then it is quite hard to work out the exact type of objects you need at the right point, for example if you take this query:
;with a as (select 1 a) select * from a
What you end up with is:
- SelectStatement that has…
- a list of CommonTableExpression that has…
- an ExpressionName which is of type Identitfier with a value of “a”
- an empty list of Identitiers which are the columns
- a QueryExpression that is of type QuerySpecification which has…
- a single LiteralInteger as the expression on a SelectScalarExpression as the only element in a list of SelectElement’s
- the CommonTableExpression has no other specific properties
- the SelectStatement also has…
- a QueryExpression that is a QuerySpecification which contains….
- a list of SelectElement’s with one item, a SelectStarExpression
- a FromClause that has a list of 1 TableReference’s which is a NamedTableReference that is…
- a SchemaObjectName that just has an Object name
If you think that it sounds confusing you would be right, but I do have some help for you in the ScriptDomVisualizer - if you give it a SQL statement it will parse it and show a tree of the objects you will get. If you do anything with the ScriptDom then use this as it will help a lot.
ScriptDom Visualizer V2
https://the.agilesql.club/blog/Ed-Elliott/2015-11-06/Tidying-ScriptDom-V…
Using the TransactSql.ScriptDOM parser to get statement counts
http://blogs.msdn.com/b/arvindsh/archive/2013/04/04/using-the-transactsq…
MSDN forum post and a great demo of how to parse T-SQL from Gert Drapers
https://social.msdn.microsoft.com/Forums/sqlserver/en-US/24fd8fa5-b1af-4…
TSql Model
The TSql Model is a query-able model of all the objects in an SSDT project, their properties and relationships. That sounds like a mouthful but consider this:
create view a_room_with_a_view
as
select column_name from table_name;
If you just have this script without the model you can use the ScriptDom to find that there is a select statement and a table reference and you could probably also work out that there is a column name but how do you know that there is actually a table called table_name or a column on the table called column_name and also that there isn’t already a view or other object called a_room_with_a_view? The TSql Model is how you know!
The TSql Model is actually not that easy to parse (there is help so fear not, I will tell you the hard way to do it then show you the easy way). What you do is to load a model from a dacpac (or you can create a brand new empty one if you like) and then query it for objects of specific types or with a specific name or even just all objects.
So imagine you open a dacpac and want to find the a_room_with_a_view view you could do something like:
var model = new TSqlModel(@"C:\path\to\dacpac.dacpac", DacSchemaModelStorageType.File);
var view = model.GetObject(ModelSchema.View, new ObjectIdentifier("a_room_with_a_view"), DacQueryScopes.UserDefined);
If you then wanted to find all the tables that the view referenced then you could examine the properties and relationships to find what you want. It is confusing to get your head around but really useful because if you know what type of object you are interested in then you can tailor your calls to that but if you just what to find all objects that reference a table (i.e. views, other tables via constraints, functions, procedures etc) it means you can really easily do that without having to say “get me all tables that reference this table, get me all functions that reference this table etc etc”.
The TSql Model API returns loosely typed objects so everything is a TSqlObject - this is good and bad but I will leave it as an exercise for you to find out why!
DacFx Public Model Tutorial
This is what first allowed me to get into the DacFx, it is the only real documentation I have seen from Microsoft and invaluable to get started
http://blogs.msdn.com/b/ssdt/archive/2013/12/23/dacfx-public-model-tutor…
Dacpac Explorer
https://sqlserverfunctions.wordpress.com/2014/09/26/dacpac-explorer/
I wrote DacPac Explorer to help teach myself about the DacFx and it turns out it is quite useful and has even been used within Microsoft as a training tool so there you go!
Querying the DacFx API – Getting Column Type Information
https://sqlserverfunctions.wordpress.com/2014/09/27/querying-the-dacfx-A…
DacExtensions
If you have tried to do something like get the data type of a column you will appreciate how much work there is to do, well as a special treat there is a github project called Microsoft/DacExtensions and it was written by members of the SSDT team in Microsoft but is open source (I love that!) what it does is take the loosely typed TSqlModel objects and creates strongly typed wrappers so if you want to see what columns are on a table, you query the model for objects of type TSqlTable (or a version specific one if you want) and you get a list of columns as a property rather than having to traverse the relationships etc.
If you do any serious querying of the TSqlModel then look at this as it really will help!
Microsoft/DacExtensions
https://github.com/Microsoft/DACExtensions/tree/master/DacFxStronglyType…
Build Contributors
The last three items, the contributors all let you inject your own code into something that SSDT does and change it - this really is huge, normally with tools you get the resulting output and that is it your stuck with it but with SSDT you can completely control certain aspects of how it works.
When you build a project in SSDT a build contributor gets full access to the validated TSqlModel and any properties of the build task so if you wanted to do some validation or change the model when it had been built then you can use this.
Customize Database Build and Deployment by Using Build and Deployment Contributors
https://msdn.microsoft.com/en-us/library/ee461505.aspx
Deployment Plan Modifiers
When the DacServices have compared your dacpac to a database, deployment plan modifiers are called and can add or remove steps in the plan before the final deployment script is generated. Again this is huge, it is bigger than huger, it is massive. If you want to make sure a table is never dropped or you don’t like the sql code that is generated then you can write a utility to change it before it is created - write the utility and use it for every build.
wowsers….
Inside an SSDT Deployment Contributor
https://the.agilesql.club/blog/Ed-Elliott/2015/09/23/Inside-A-SSDT-Deplo…
Repository of sample deployment contributors
https://github.com/DacFxDeploymentContributors/Contributors
Deployment Contributor that lets you filter deployments (don’t deploy x schema to y server etc)
http://agilesqlclub.codeplex.com/
Deployment Plan Executor
Where deplotment plan modifiers can change the plan and add, edit or remove steps a plan executor gets read only access to the plan and is called when the plan is actually executed. The example on MSDN shows a report of the deployment to give you some idea of what you can do with them.
Walkthrough: Extend Database Project Deployment to Analyze the Deployment Plan
https://msdn.microsoft.com/en-us/library/dn268598.aspx
Help and Support
I created a gitter room to answer questions and give advice on writing deployment contributors but I would be more than happy to help answer questions on them or any part of the DacFx so feel free to drop in:
https://gitter.im/DacFxDeploymentContributors/Contributors
All welcome :)
Comments:
Anonymous
February 10, 2016 - 13:16
Data loss property and table rebuild process
In dacpac deployment
Though Data loss is ok for me , Reducing column (x) size from 50 to 25 on table (y) leads to
1. Temp table creation
2. Moving data from original table (y) to temp table with casting column(x) with 25
3. Drop original table (y)
4. Rename of temp table to original table (y)
5. Rename of all constraints/indexes
Why it does all the above when I selected data loss is ok ?
Why don’t it alter directly to 25 – like how we do In ssms? (ALTER statement)
It takes lot of time in data transfer especially if I have millions of record in it. point #2 above
What is the solution for this ?
Ed Elliott
February 15, 2016 - 15:41
You could write a deployment
You could write a deployment contributor but it is quite a lot of work. If this is something that you do only occasionally then the easiest is to make the change in your ssdt project and then use a pre-compare script which you run *before* you run sqlpackage to dpeloy the dacpac. In the pre-compare script you do the alter so when sqlpackage runs it already finds the column is of the correct length so makes no change.
Anonymous
February 11, 2016 - 06:16
SQLServer Data Tools : How to disable and enable DML Trigger.
In dacpac deployment
When I go with smart default , it automatically adds a UPDATE statement , here we should have an option to disable, enable DML trigger.
In my scenario
1. Smart default trys to UPDATE
2. Existing Trigger fires
3. Whereas my corrected new trigger yet to deploy
4. This causes error , since trigger alter trigger placed after smart default update.
Ed Elliott
February 15, 2016 - 15:43
I would do two things,
I would do two things, firstly raise an issue on the microsoft connect site and it may get fixed in the future and work around it yourself using the pre-compare script I mentioned above. It is a bit of a pain but will get it up and running.
Anonymous
February 25, 2016 - 12:24
Hi In my case it is not
Hi In my case it is not possible to do pre-compare manually, since it goes as part of installer and 100’s of clients ..
Thanks