
SSDT Deploy / Publish Performance
Publishing dacpac’s is a little bit of a pain when you have multiple databases, it can easily start to take minutes to hours to deploy changes depending on how many databases and the size of those databases. I wanted to understand more about the publish process and what we can do to speed it up as much as possible so I did some digging and this is a randomish post about how it all works and what we can do to make it faster.
Process Overview
Roughly speaking the process for deploying dacpacs is:
- 1. Open dacpac (zip file)
- 2. Open database
- 3. Compare dacpac to database
- 4. Come up with a list of changes
- 5. Generate the T-SQL for the changes
- 6. Run the deploy script
1. Open the dacpac (zip file)
The dacpac contains the xml representation of the model of the database and the original source code. To be able to deploy changes we need the original source code - the model contains the definitions of the objects such as which columns the table has and the parameters a stored procedure has but not the body of the stored procedure including comments.
The dacpac is a zip file, this means to read from it the deployment must create a file handle to the dacpac and uncompress anything it wants to read (or compress anything it wants to write), the larger the dacpac logically the longer it will take to decompress and also read from disk so there are our first two important things to note, the deploy will need:
- CPU to decompress the contents of the dacpac
- Fast disk as it has to read from disk
When you run the publish, by default the model is read from disk into memory, however, for very large dacpac’s you might find that you don’t have enough memory for it - a windows system with low memory is bad, two things happen:
- The paging file is used
- Applications are told to free memory
This is painful for an application and when you get paging, especially on non-ssd drives, you are going to find everything about the whole system slow.
If you have a large model in your dacpac and you don’t have much memory then you will probably need to load the model from disk rather than into memory, but you best make sure you have an ssd to run it from!
For more details on how to do that see: https://redphoenix.me/2013/06/14/why-is-sqlpackage-using-all-the-build-s… (Richie Lee FTW!)
2. Open database
The database contains all sorts of goodies like the version that will be deployed to, the database settings and the definitions that will be compared to the dacpac to see what changes need to be made. If your SQL Server responds slowly then the publish will be affected by that so make sure your SQL Server box is up to scratch and expect slower deploy times on resource limited instances.
3. Compare dacpac to database
I had always wondered how they compared the two different objects so I bust out reflector and used it to have a poke about. What happens is a model is build of the source and target - a model is a representation of each object, it has its name, its properties and relationships to other objects for example a table has a relationship to its columns and each column has a relationship to its type (not a property of the type).
If you think about this it means, for each deploy we actually need to store the model of both the database and the dacpac so doubling the size requirements - this isn’t to say an exact double of the size of the source code becauuse what it compares is things like the object properties and relationships but also the tokens that make up the body of the object, so there are a lot more objects that are created around the code. In short if your source code is 100 mb you will need some multiple of 2 * 100mb to upgrade an existing database - I am not sure if there are any figures to show what that multiple is but if you do a publish and you run low on memory or you get lots of garbage collection in your deploy then consider either storing the model on disk or throwing in some more memory.
There are a couple of interesting extra things that happen, in particular to do with the size of code in objects and how much to store in memory, to store in memory compressed or to write to disk. If for example you had a stored proc that was less that 500 characters long, the publish will store it in memory.
If the string representation of a procedure was over 500 characters but less than 16 thousand characters the it will be stored in memory but compressed first.
Finally if the stored proc (I am using procs as a example but I think it is any code unit minus the create + name so everything after “as”) is over 16 thousand characters then a temp file is generated in your user temp folder and the contents are written to that.
So three different behaviours depending on the size of your objects:
- Under 500 chars - you need memory
- Over 500 chars, under 16,000 you need memory and CPU
- Over 16,000 chars you need memory and fast disk for your temp folder
I created three demo databases and deployed them over and over, the first contains a couple of hundred procedures with slightly under 500 characters, the second with slightly over 500 characters and the last with slightly over 16,000 characters.
When I ran the publish this is what they looked like:
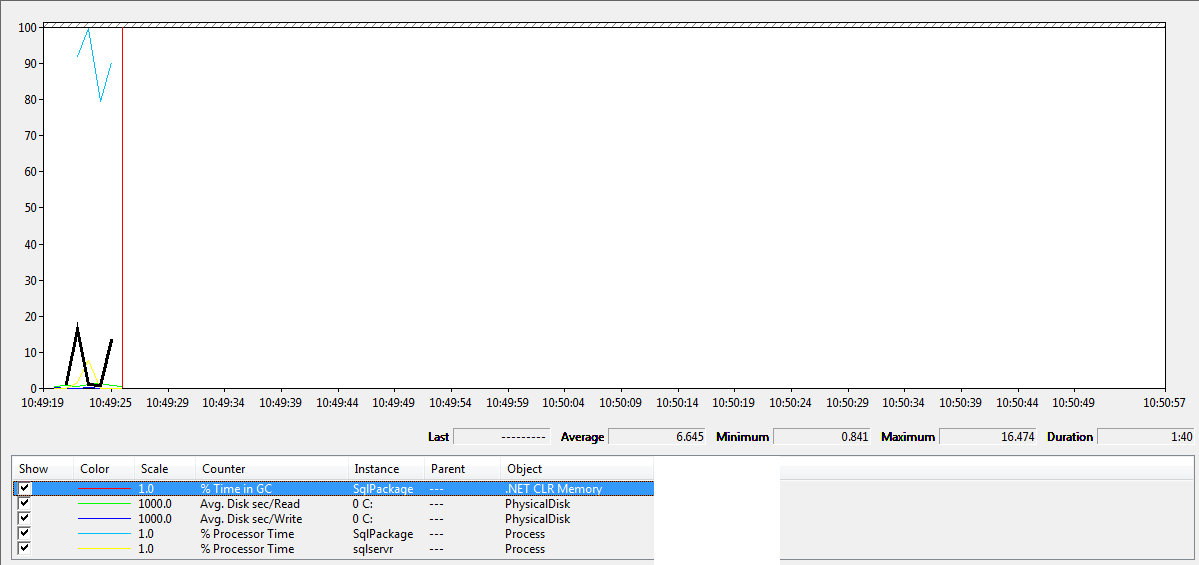
Under 500 char procs:
Slightly over 500 char procs:
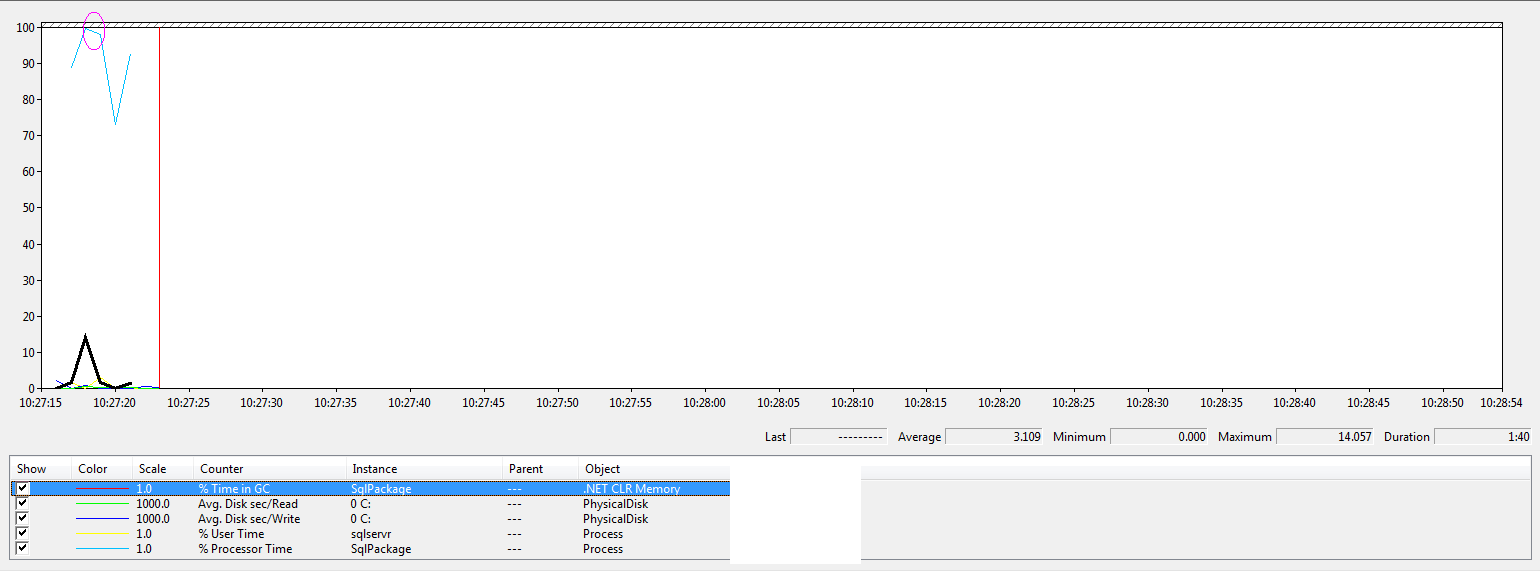
What we can see here is that the under 500 char procs, takes the least amount of time but the interesting thing is the database with slightly over 500 chars procs has a little bit of extra umpf from the CPU - I have showed this by using the pink circle - both deploys follow the same pattern for sqlpackage.exe CPU usage - it goes from around 90% cpu up to 100% and then drops down sharply to around 80% and then back up to 90% but the second project with the slightly larger procs - also has an extra splurge of CPU which I am putting down to the extra compression that those strings are getting - it certainly tallies up, even if it is not scientific :)
Aside from the extra CPU usage they are pretty similar, the black highlighted line is garbage collection and the way this counter works is every time it changes, it is doing some garbage collection - the first version does I think 3 collections and the seconds does 4 which sort of makes sense as once the strings has been compressed the original strings can be thrown away.
It is when we start to look at the database with lots of objects over 16,000 characters long we see some interesting things and some other forces come into play:
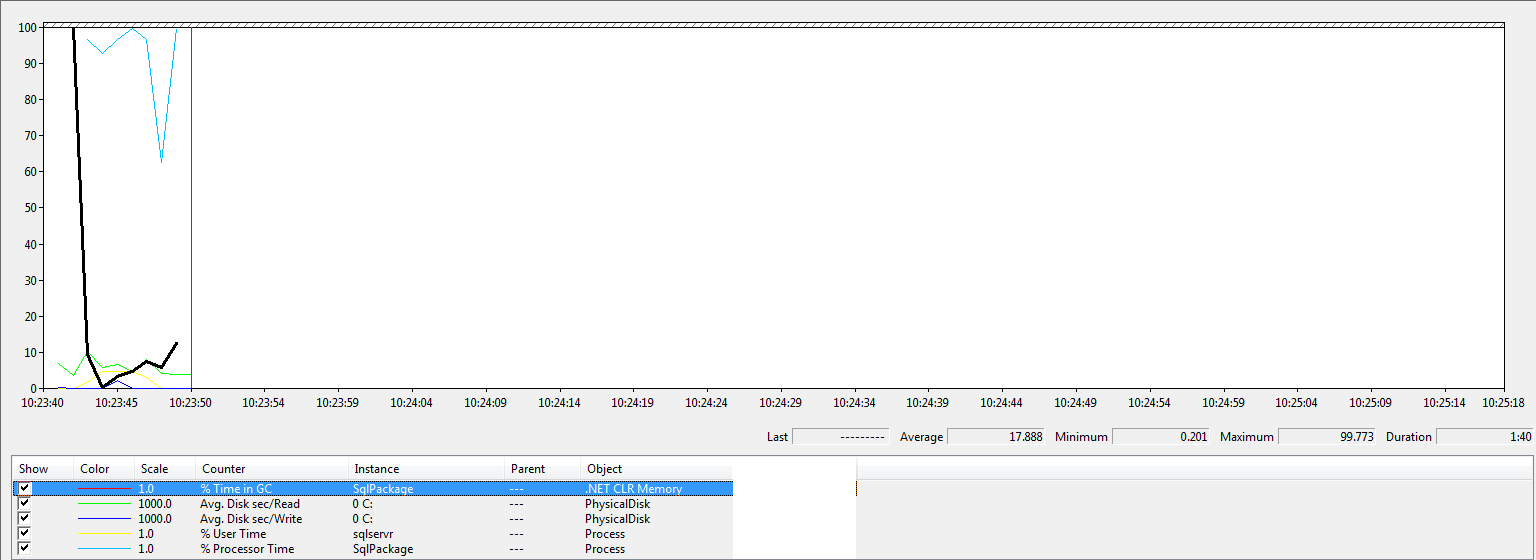
The first thing to note is the garbage collection, there are like 8 changes to the line so 8 sets of garbage collection that happen which is expensive for a .net app. We get much more processor usage for a more prolonged time and we really start to see some disk activity, write activity just has one peak while the files are written but reading stays quite high throughout the whole process. It could be that it is sql reading from disk (my demo was from a single ssd with a local sql instance) but we can see after the sql cpu settles down the green disk read line stays high so it is unlikely to be pure sqlserver.exe.
What does this tell us?
Well if you have large objects, multi-thousand line stored procs then you better get yourself some serious ssd’s to deploy from. If you have smaller objects then you’ll need CPU and memory - don’t scrimp here!
4. Come up with a list of changes
So when the properties and tokens in the source / destination object have been compared they are added to a list of modifications - this is fairly straight forward but that is not the final list of modifications because there are lots of options to customize the deployment such as ignoring certain things - what happens next is that there is some post-processing done on the list to remove anything that the options say should be removed.
We then get the opportunity to interrupt the deploy process with a contributor and remove steps as we want - if we do that anything we do is overhead so be warned, be fast in what you do or slow down the whole process!
There are some things like default constraints, these are stored differently in SQL Server to our project - so when a difference is found, as part of the post-processing each constraint is “Normalized” using the script dom and a visitor to find out if the changes are actually different or just appear different - this means that we don’t keep getting constraints deployed over and over (a relatively new feature as this was something that used to happen a lot - a great new feature added by the SSDT BTW!) but it does mean for every default constraint we need to go through this normalization using the script dom which isn’t exactly lightening fast.
Takeaways from this are that the deploy does a lot of things to help us - if it was a straight string comparison then it would be faster but the deploy options would not be as configurable. The more objects you have, the longer the deploy will take!
5. Generate the T-SQL for the changes
6. Run the deploy script
I’m going to stop this post here - I think these are a bit more straight forward, the more things you have to change, the more time it will take :)
Summary
If the deploy is slow, use perfmon measure the cpu, disk and garbage collection of sqlpackage.exe (or whatever is doing the deploy) - have a think about whether streaming the model from disk would be better and if you are CPU bound add a more powerful CPU, if you are low on memory, add more memory and if you are on an old slow disk - put it on an ssd.
If you are low on CPU you might be tempted to add more CPU’s - understand that a single deploy happens in serial so adding more CPU’s won’t make a deploy quicker if this is the only thing running on a box - if it is fighting for resources then more CPUs may help.