
SSDT How To Fix Error SQL17502
TLDR:
If you build an SSDT project you can get an error which says:
“SQL71502: Function: [XXX].[XXX] has an unresolved reference to object [XXX].[XXX].”
If the code that is failing is trying to use something in the “sys” schema or the “INFORMATION_SCHEMA” schema then you need to add a database reference to the master dacpac:
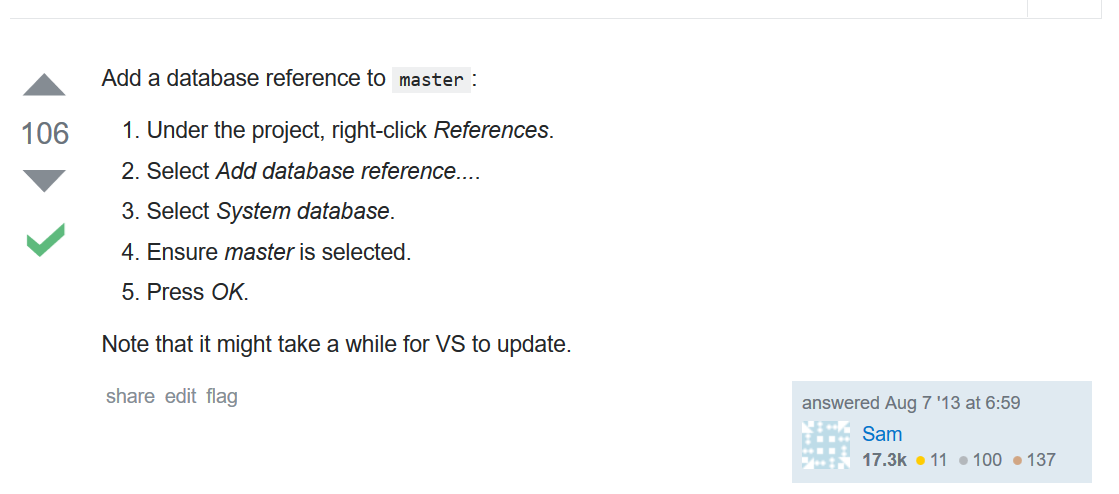
Add a database reference to master:
- Under the project, right-click References.
- Select Add database reference….
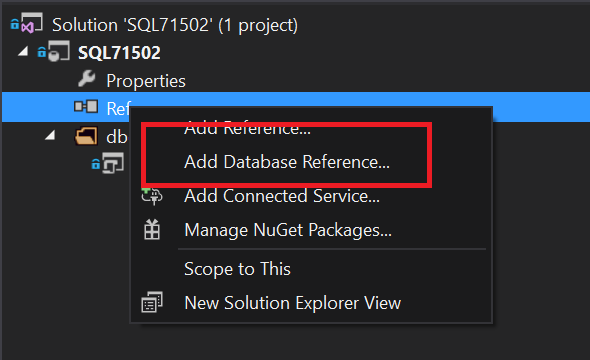
- Select System database.
- Ensure master is selected.
- Press OK.
Note that it might take a while for VS to update.
(Note this was copied verbatim from the stack overflow question with my screenshots added: https://stackoverflow.com/questions/18096029/unresolved-reference-to-obj… - I will explain more if you get past the tldr but it is quite exciting! )
NOT TLDR:
I like this question on stack overflow as it has a common issue that anyone who has a database project that they import into SSDT has faced. It might not affect everyone, but a high percentage of databases will have some piece of code that references something that doesn’t exist.
The question has a few little gems in it that I would like to explore in a little more detail because I don’t feel that a comment on stack overflow really does them justice.
If we look at the question it starts like this:
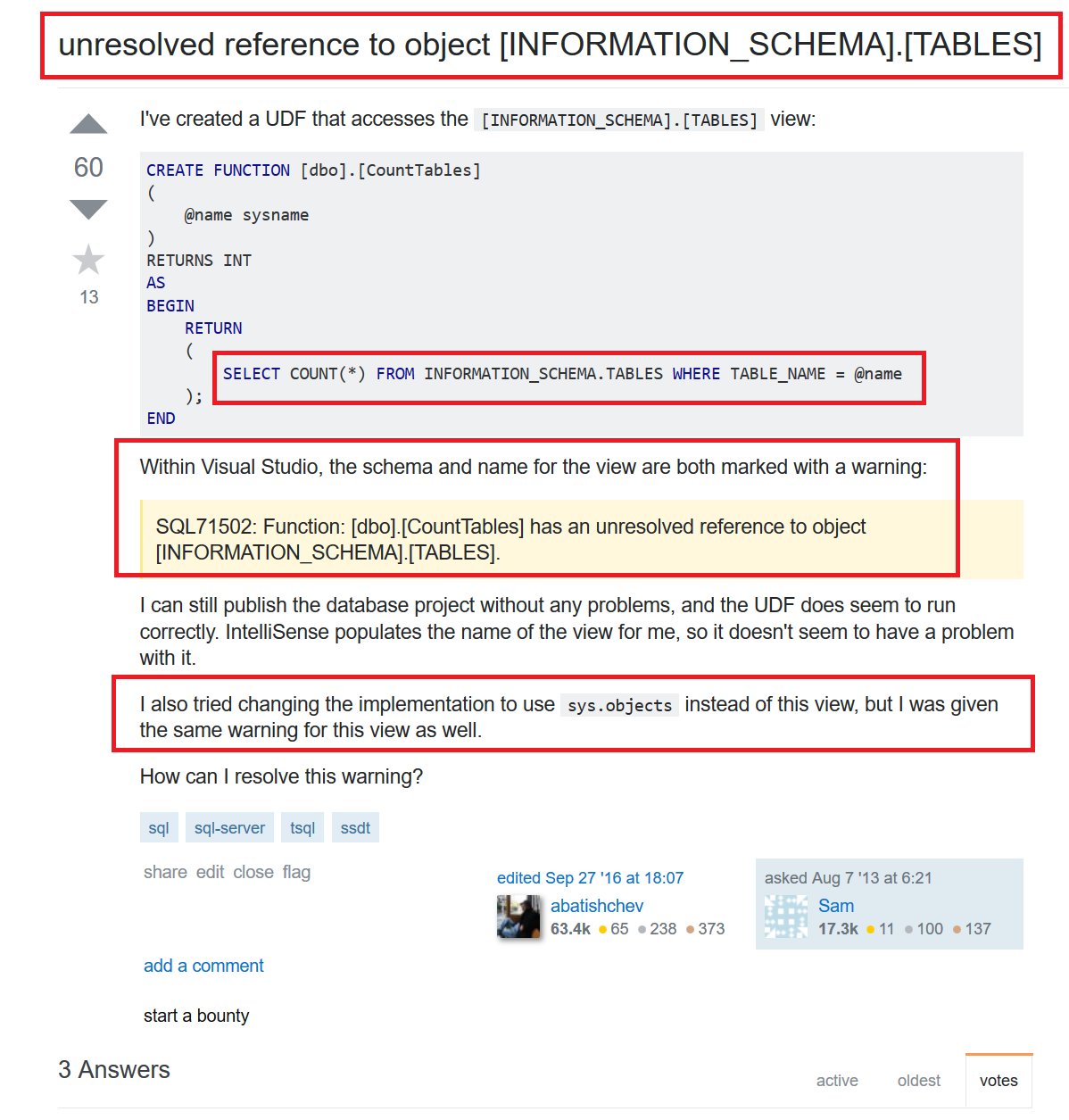
The first thing is the error:
unresolved reference to object
What does this mean? When you write some code in SSDT, a stored procedure, function, foreign key (admit it, you weren’t expecting foreign key were you!) SSDT validates that when the code references another object that the other object exists and is usable in that scenario. So if you have a table called “dbo.abc” and you made a mistake and typed “select a from dbo.ab3” then SSDT will notice this and give a warning or an error (more on this later).
After the unresolved reference we have
[INFORMATION_SCHEMA]
.
What is the INFORMATION_SCHEMA? Well, one of the most exciting things about modern RDBMS’s (I say modern but basically forever) is that the SQL language specification dictates that the language used by an RDBMS is capable of querying and interacting with the environment as well as the data. Think of an RDBMS as being like a DevOps dream decades before Gene Kim et al. sat down at a typewriter and spilt the Pheonix project onto paper. The INFORMATION_SCHEMA is a way to query things about the database environment. In the example in the question, they are using it to find the number of tables that exist that have a specific name (tip: it will either be 1 or 0).
In SQL Server, the INFORMATION_SCHEMA is in the master database and is special in that you can type “SELECT * FROM INFORMATION_SCHEMA.SOMETHING” and you don’t have to type the name of the master database first like “SELECT * FROM master.INFORMATION_SCHEMA.SOMETHING”. This is nice as it saves our little typing fingers but also a little hard for SSDT as it means that it has something else to handle.
Moving on we have:
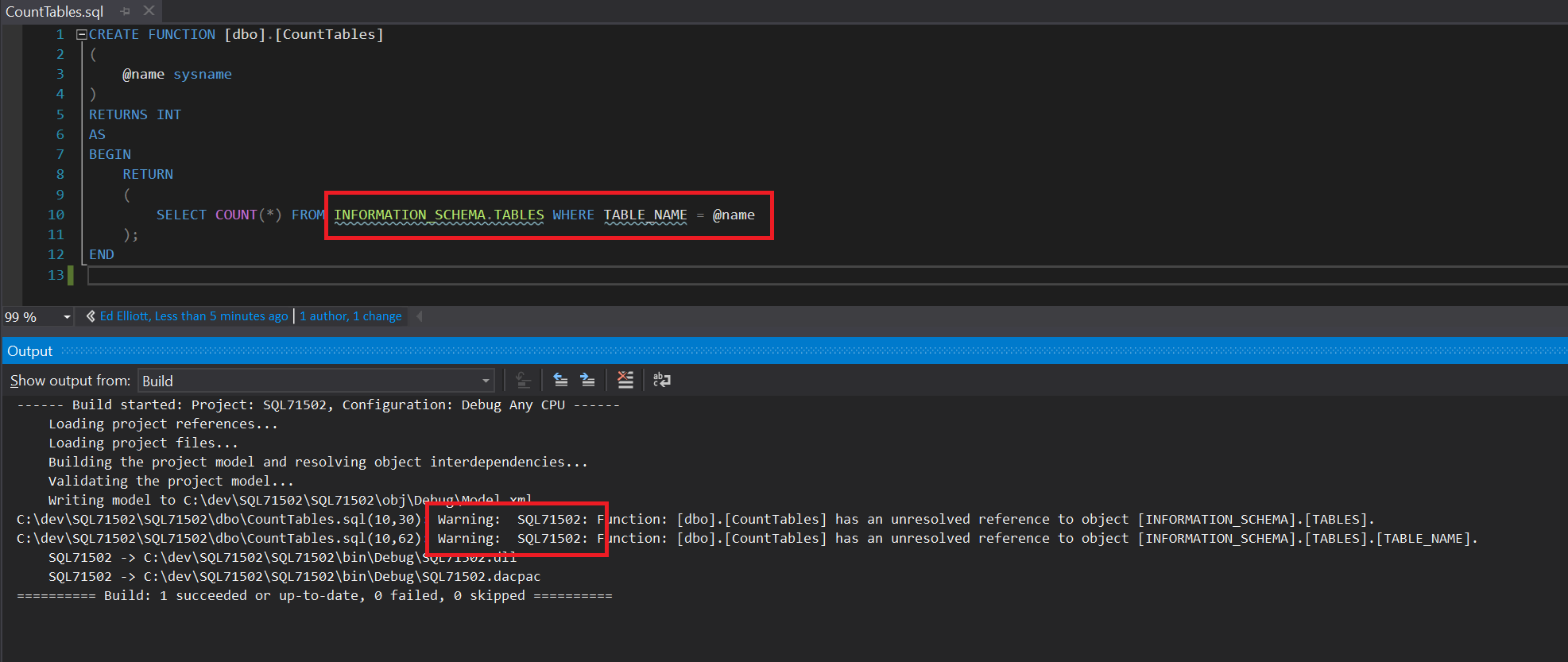
Within Visual Studio, the schema and name for the view are both marked with a warning.
There are two possible outcomes in SSDT when it can’t find a referenced object, the default is what has happened here there is a warning, and you get a squiggly line under the code:
The last piece of the question is interesting,
I also tried changing the implementation to use sys.objects instead of this view, but I was given the same warning for this view as well.
The sys schema is similar to the INFORMATION_SCHEMA schema except it is SQL Server (and Sybase ha ha) specific rather than cross-platform as INFORMATION_SCHEMA is supposed to be.
The final thing about the question is it is by someone called Sam with (at today’s count) 17 thousand stack overflow points, that is some serious stack overflowing!
The Answers
If we look at the first answer we have:
The answer is spot on and fixes the error for the view Sam is talking about in the INFORMATION_SCHEMA. I like that stack overflow lets someone ask and then answer their own question. He was stuck, he asked, he found the answer and instead of leaving a page without an answer like DenverCoder9, he found the answer and left it for the world:
Answer 1 Comments
The first comment is by the great Peter Schott (B | T):

To give a bit of background on this, Peter has a team where some people have installed Visual Studio to the C drive and some to the E drive, and they were getting errors when referencing the master.dacpac.
What happens with database references is that you get a block of XML that looks something like this added to your .sqlproj file:

When SSDT tries to resolve a reference, it looks at the “Include” attribute on the “ArtifactReference”, and if it doesn’t find that then it looks in the “HintPath” and failing that I think it looks in the build bin directory, but we won’t rely on that working.
This reference is from a Visual Studio 2017 project and you can see that the “HintPath” is not hardcoded to the C drive but instead uses a variable to get to the dacpac. This was not always the case, a while back this was hardcoded using “..” relative paths (WTF!), a full discussion on this pain was:
https://social.msdn.microsoft.com/Forums/sqlserver/en-US/b6f5584e-4533-4…
So this fixes the shared dacpac from different system dacpac’s but what if the code we are referencing was in a user dacpac? How do we set the reference and allow people to map their source code folders or build servers to the same projects?
There are two approaches. The first is to put the dacpac’s in a known location “c:\dacpacs”, “\\dacpacserver\dacpacs” etc. and always use that path. The second option is to check the dacpac’s into source control with the solution and referencing using relative paths.
Both ways work, do what is best for you.
The next two comments are:

Veysel chose to copy the dacpac’s into the solution folder, yay to Veysel.
Now Orad seems to have got stuck as they have already referenced the master dacpac. As a guess, I would say Orad’s problem is either that they are referencing an object in another schema and has the same error but not for the sys or INFORMATION_SCHEMA schemas or Orad has mistyped a referenced object and the warning or error is actually valid.
They should re-check the code is correct. It is possible that they are referencing an object in the INFORMATION_SCHEMA that isn’t in the dacpac. If this was the case then Orad could declare the missing object themselves, and it would probably just work, but we would need to keep his reference to master, otherwise, Orad would lose their “create schema INFORMATION_SCHEMA” statement in his master.dacpac.
After Orad’s comment we have:
Martin is happy :)
NYCdotnet less happy but they do mention something interesting that there is a setting under “Online Editing”. SSDT has a couple of different usage scenarios. The first, and in my opinion, the main reason for using SSDT is the offline editing where you edit T-SQL code offline, build and validate before you get anywhere near any a database.
The second scenario is online where you connect to a database and change the code like an old school DBA with a live production database in SSMS. The setting in this comment talks about the online version and doesn’t fix the warning or error in the offline scenario which is probably being mentioned in this question (if this isn’t about the offline version then I am going to hang up my technology boots).
The final comment on the first answer is by Scarl:

Scarl I guess either doesn’t have an SSDT database project open or the installation has failed, try re-installing SSDT and creating a new database project from scratch.
Answer 2
techfield has suggested this:
In Sam’s original question, they mention that they get a warning and the project still deploys but techfield points out that this can cause an error and if you get an error you can’t deploy a project as it won’t build. This can result in much frustration.
The difference between this error being displayed as a warning which can be ignored (unless you have “treat all warnings as errors” which of course you should but don’t) and an error which stops the dacpac from being built is this setting. You can either edit the .sqlproj file and change the XML, or you can go to the properties of the project and tick the box:
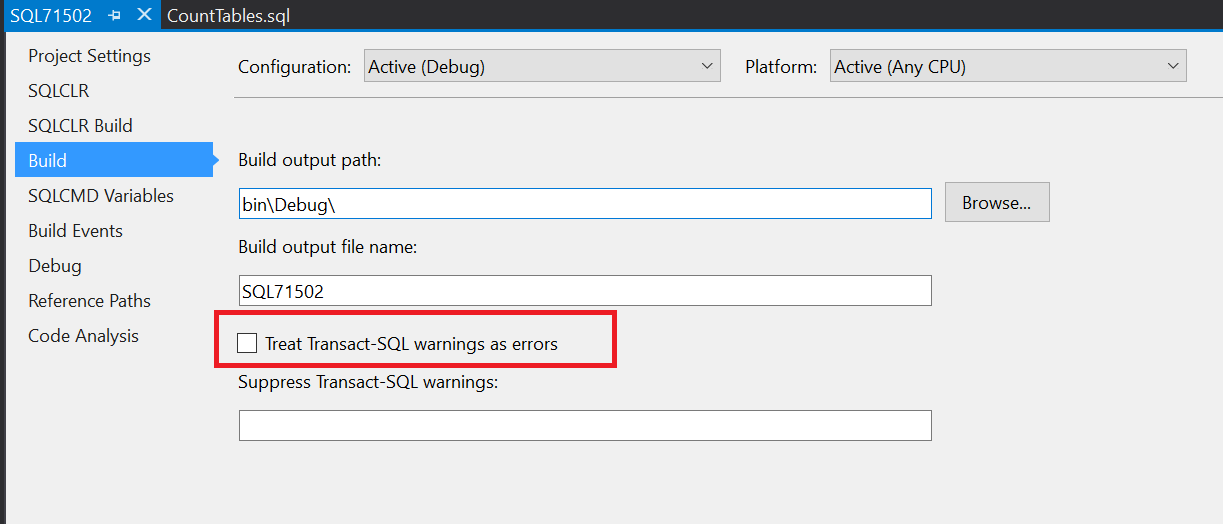
Jowen then correctly said you shouldn’t turn off errors willy nilly - personally I always check this and enforce it unless I am working with an “inherited” database where it isn’t possible but over time make it possible and then check it. When it is possible, I then work towards clearing the warnings if practical.
Final Answer
The final answer is by Russell:
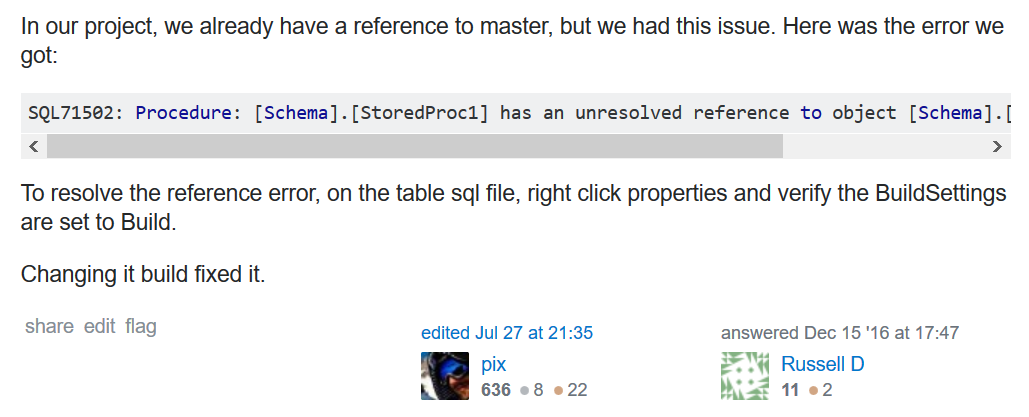
What has happened in Russell’s case is that he has a table in a project that is in a .sql file but the build properties of the file “Build Action” is not set to build so although the file exists and the table is valid it is invisible to SSDT. Set the “Build Action” on the file properties in Visual Studio to “Build” and it will be included and the reference can be validated.
Try for yourself
I have setup a GitHub repo to show this error in all of its glory in case you would like to play along at home.
If you would then get yourself a command prompt that can run git and do:
git clone https://github.com/GoEddie/SQL71502.git
I know I called the project the error number, this is like inception in real life. If you go ahead and open the SQL71502.sln solution when you build you should get a warning and also the reference to INFORMATION_SCHEMA should show a blue squiggly line:
Note about the warning, the warnings are only displayed when a file is compiled, if you build then build again without changing a file it won’t get re-compiled so all your warnings will disappear! The warning is still there, add a new line or something to the file to cause a rebuild and the warning to be re-displayed. Because of this feature, I sometimes do a visual studio clean and re-build when using SSDT to get a full overview of the issues.
Let’s go hardcore and set the project to treating T-SQL warnings as errors. Go and run:
git checkout 1-errors-as-warnings
You will probably need to reload the solution in Visual Studio and then when you build you will get an error instead of a warning, and the dacpac won’t build.
To fix the error, we now need to add the database reference to the master database, follow the advice from the stack overflow question above to add the reference and then when you build you should get a successful build. If you didn’t want to add it yourself you could run:
git checkout 2-fix-error
When running git checkout, if you have changed any files you will get an error running “git checkout – .” will reset git and let you switch branches (it throws away any changes so don’t do it unless you want exactly that).
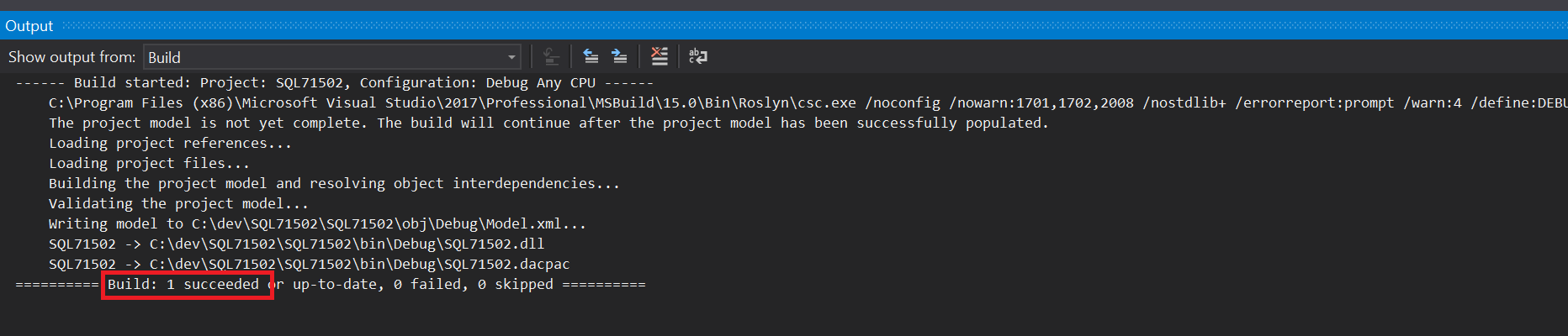
With the database reference added we could rebuild and there should be no error or warning:
Now, if instead of a system reference we had a missing user reference, we would get a similar thing with the same error number. Switch to the next branch:
git checkout 3-broken-user-reference
you will see this error:
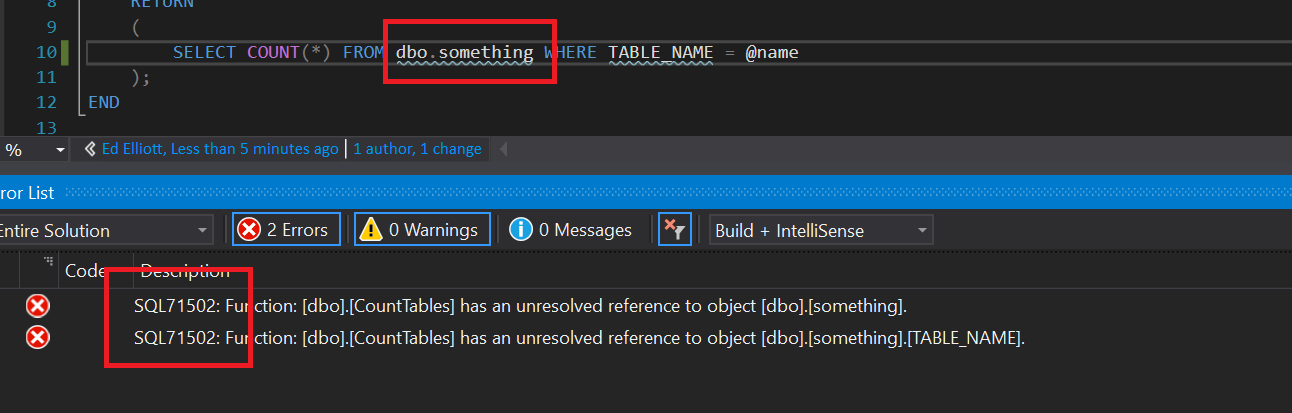
We fix it by creating the object that it was expecting:
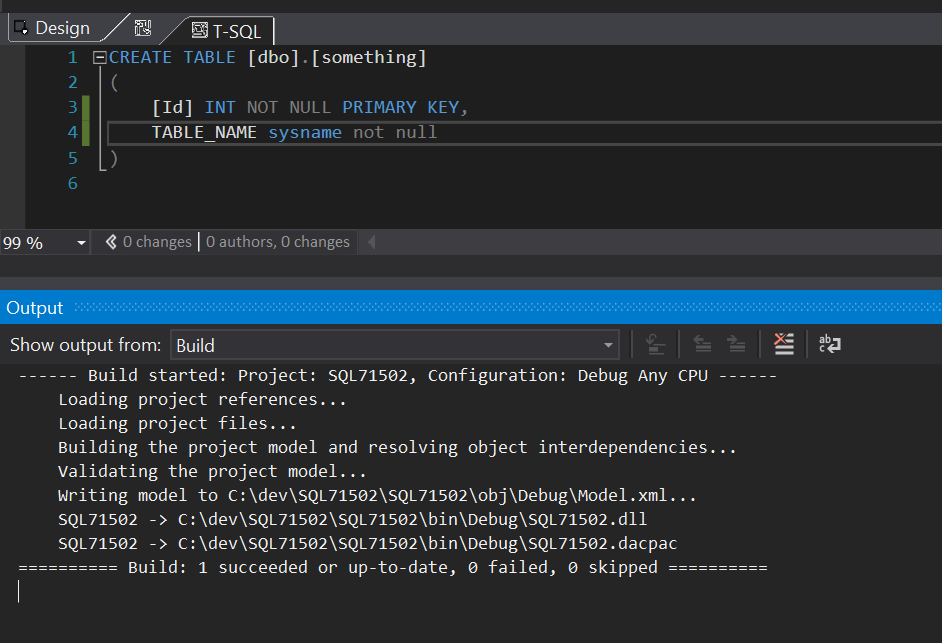
and then it will build successfully:
Happy days.
I hope no one minds we copying and pasting from stack overflow, I guess it is the modern way :)