
Using Spark Connect from .NET
Introductory Ramble
Spark Connect
In July 2022, at the Data and AI summit, Apache Spark announced “Spark Connect,” which was a way of connecting to Apache Spark using the gRPC protocol rather than using the supplied Java or Python APIs. I’ve been using Spark since 2017 and have been completely obsessed with how transformative it has been in the data processing space.
Me
Over the past couple of decades working in IT, I have found a particular interest in protocols. When I was learning how MSSQL worked, I spent a while figuring out how to read data from disk via backups rather than via the database server (MS Tape Format, if anyone cared). I spent more time than anyone should learning how to parse TDS (before the [MS-TDS] documentation was a thing)—having my head buried in a set of network traces and a pencil and pen has given me more pleasure than I can tell you.
This intersection of protocols and Spark piqued my interest in using Spark Connect to connect to Spark and run jobs from .NET rather than Python or Scala.
Side Note - I spent a lot of time in the past contributing to the Microsoft .NET for Apache Spark project (https://github.com/dotnet/spark) - even writing a book about it (https://link.springer.com/book/10.1007/978-1-4842-6992-3?source=shoppingads&locale=en-gb&gad_source=1&gclid=CjwKCAiAkp6tBhB5EiwANTCx1JfCNSft8EvZpFGUg6rzt3LIGBI8Pqip6VVVZvIzpHF5pKMqcob7DBoCcSgQAvD_BwE).
Although the project’s status is currently unknown and undoubtedly unloved, I hope that the community, in partnership with Microsoft, can bring it back to life, but that is for another day. This work may help the main project stay alive in one form or another.
In this post, I will look at what is available today and show an example of connecting from .NET to Spark using the Spark Connect gRPC protocol.
References
There isn’t too much in the way of documentation, but we do have some super helpful sources of information:
Spark Connect Server
I’ll cover this briefly, instead of running jobs using spark-submit or spark-shell, we need to start up a server to which our client will connect. I will cover Databricks another time, but to get this working locally in your spark installation directory, you need to run:
$SPARK_HOME/sbin/start-connect-server.sh --packages org.apache.spark:spark-connect_2.12:3.4.0
You’ll need the spark connect package that matches your version of spark, I am using 3.4.0. This is obviously for a Mac, I’ll look at Windows in another post, but maybe using WSL is wise.
When you run that you should have output that says something like “logging to xxx” - have a look in the xxx to see if the server is started and is listening.
Spark Connect Client
I have created a repo that goes along with this post: Spark Connect Client Repo
The gist of the process to get this running is:
- Create a project
- Reference the Grpc packages
- Get a copy of the proto files
- Generate the C# code from the proto files
- Create a client that connects to the server and runs a job
- Party time (also do it from VB.Net as well for fun)
References
If you add references to these packages:
- Apache.Arrow
- Google.Protobuf
- Grpc.Core.Api
- Grpc.Net.Client
- Grpc.Tools
That should be a good start, then grab the proto files from https://github.com/apache/spark/tree/master/connector/connect/common/src/main/protobuf/spark/connect.
If we step back a minute and think about how this should be structured, the solution is something like:
- Grab the proto files from the Spark repo
- Use the Grpc tools to generate C# code
- Reference the C# generated code
- Profit
I don’t want to have someone else’s code in my project. Ideally, we would isolate the Spark proto files and the generated code in a separate project and reference that project. If you have zero care for your work, feel free to shove everything into a single project.
So, given that then, the way I think it should be structured is that I have a separate project for the proto files - what you do is, of course, up to you, but it works for me:
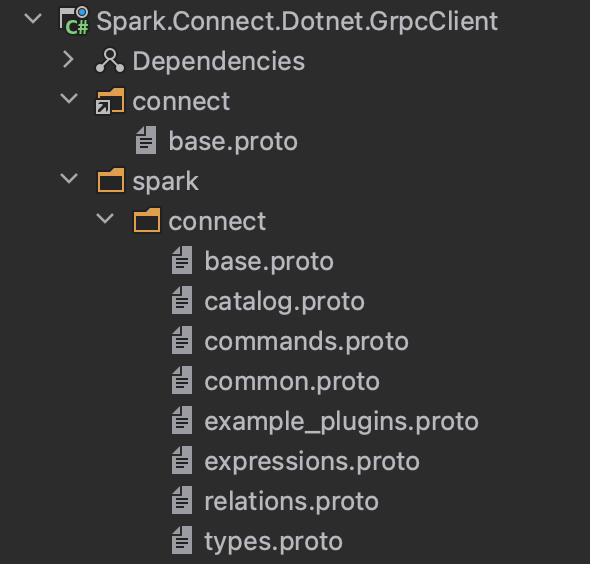
There is a bit of weirdness where I created a folder called connect and included the base.proto file and the version in the root connect folder has the Proto build action, and the version in the “spark/connect” folder has None as the build action:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net7.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
<NoWarn>8981</NoWarn>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Apache.Arrow" Version="13.0.0" />
<PackageReference Include="Google.Protobuf" Version="3.24.4" />
<PackageReference Include="Grpc.Core.Api" Version="2.57.0" />
<PackageReference Include="Grpc.Net.Client" Version="2.57.0" />
<PackageReference Include="Grpc.Tools" Version="2.40.0">
<IncludeAssets>runtime; build; native; contentfiles; analyzers; buildtransitive</IncludeAssets>
<PrivateAssets>all</PrivateAssets>
</PackageReference>
</ItemGroup>
<ItemGroup>
<Content Update="spark\connect\catalog.proto">
<Link>connect\catalog.proto</Link>
</Content>
<Content Update="spark\connect\commands.proto">
<Link>connect\commands.proto</Link>
</Content>
<Content Update="spark\connect\common.proto">
<Link>connect\common.proto</Link>
</Content>
<Content Update="spark\connect\example_plugins.proto">
<Link>connect\example_plugins.proto</Link>
</Content>
<Content Update="spark\connect\expressions.proto">
<Link>connect\expressions.proto</Link>
</Content>
<Content Update="spark\connect\relations.proto">
<Link>connect\relations.proto</Link>
</Content>
<Content Update="spark\connect\types.proto">
<Link>connect\types.proto</Link>
</Content>
</ItemGroup>
<ItemGroup>
<Protobuf Include="spark\connect\base.proto">
<GrpcServices>Both</GrpcServices>
<Access>Public</Access>
<ProtoCompile>True</ProtoCompile>
<CompileOutputs>True</CompileOutputs>
<OutputDir>obj\Debug/net7.0/</OutputDir>
<Link>connect\base.proto</Link>
</Protobuf>
<None Remove="spark\connect\catalog.proto" />
<Protobuf Include="spark\connect\catalog.proto" />
<None Remove="spark\connect\commands.proto" />
<Protobuf Include="spark\connect\commands.proto" />
<None Remove="spark\connect\common.proto" />
<Protobuf Include="spark\connect\common.proto" />
<None Remove="spark\connect\example_plugins.proto" />
<Protobuf Include="spark\connect\example_plugins.proto" />
<None Remove="spark\connect\expressions.proto" />
<Protobuf Include="spark\connect\expressions.proto" />
<None Remove="spark\connect\relations.proto" />
<Protobuf Include="spark\connect\relations.proto" />
<None Remove="spark\connect\types.proto" />
<Protobuf Include="spark\connect\types.proto" />
</ItemGroup>
</Project>
Warning
Ok, so if you are familiar with Spark, you will be familiar with the DataFrame API and cool things like SparkSession and SparkSessionBuilder. In this world of Spark Connect, we don’t have any of these - if we want them, we will need to create them as wrappers around the API. In a future post (insert promise to deliver an article that I may never deliver read in an evil villain voice), I’ll go into some more detail about what the hell we use if there are none of the objects we know and love (relations, baby, we are going to have relations and plans and make plans with the relations and it is going to be amazing).
If I were you, I would go with it. I promise everything will be fine - I have seen it work, and it is, let me assure you, beautiful.
Another warning
We are working at a low level here my friends, df.show() might print out to your console in your world, but df.show() in this world will send the (Arrow) output into the void until we write some code. Today, we will keep it simple: connect to the server, create a DataFrame, and write it out.
Fact of the day
Fun fact of the day for those paying attention is that I always knock on the fridge door before opening it, just in case there’s a salad dressing 😂, sorry.
Connecting
var channel = GrpcChannel.ForAddress("http://localhost:15002", new GrpcChannelOptions(){});
await channel.ConnectAsync();
var client = new SparkConnectService.SparkConnectServiceClient(channel);
Running a Job
I think a nice thing to prove this whole thing works is to use my favorite spark command, Range (it is my fav command as I spent too long in MSSQL trying to cross-join system tables to generate new rows, ok, let me have it and be happy for me) to create a DataFrame and then write out that DataFrame to a parquet file.
Ok, here we will just get on with it and worry about what it means later. This post aims to show we can connect to spark from C# (and VB.Net for laughs) and run a job.
The first step is to create the relation, which will store the plan step for the Range command. Our job is to create a plan which will be sent to the Spark server to execute.
//Create a range relation - think of a relation here as a `DataFrame`
var rangeRelation = new Relation()
{
Range = new global::Spark.Connect.Range
{
Start = 10,
End = 100,
Step = 5,
NumPartitions = 1
}
};
In this case, we want to create a single relation, but if we want to read two files, union them, and then join them with another file, we would need three relations which would all be chained together to make a tree of relations.
//Create a plan - our job is to create a plan and send that plan over to the spark server which executes it
var writeParquetFilePlan = new Plan()
{
Command = new Command()
{
WriteOperation = new WriteOperation()
{
Mode = WriteOperation.Types.SaveMode.Overwrite,
Source = "parquet",
Path = "/tmp/wow.parquet",
Input = rangeRelation
}
}
};
Now what we have is an object in .NET which represents a plan, lets print it out to see what it actually looks like:
//What does the whole plan look like?
var parsedJson = JsonConvert.DeserializeObject(writeParquetFilePlan.ToString());
Console.WriteLine(JsonConvert.SerializeObject(parsedJson, Formatting.Indented));
{
"command": {
"writeOperation": {
"input": {
"range": {
"start": "10",
"end": "100",
"step": "5",
"numPartitions": 1
}
},
"source": "parquet",
"path": "/tmp/wow.parquet",
"mode": "SAVE_MODE_OVERWRITE"
}
}
}
The bit I wanted to point out is the range relation, we created it and nothing happened - this exactly the same as in Spark, we have transformations and commands, Range is a transformation, and we need to execute it to get the results. We could have many many transformations until a command causes something to happen. One thing to note is that we can generate as many plans as we want, to actually do anything we need to send the plan off for execution:
client.ExecutePlan(new ExecutePlanRequest() { Plan = writeParquetFilePlan }, new Metadata());
and that is it, when we run it and I do a ls /tmp/wow.parquet I see:
ls /tmp/wow.parquet
_SUCCESS part-00000-5677a77c-9787-4aec-8fdc-d900acb0ce63-c000.snappy.parquet
OMG.

VB.Net
I promised!
Imports Grpc.Core
Imports Grpc.Net.Client
Imports Spark.Connect
Module Program
Sub Main(args As String())
Task.Run(function() RunSparkJob()).Wait()
Console.WriteLine("Done")
Return
End Sub
Private Async Function RunSparkJob as Task(Of Boolean)
Dim channel = GrpcChannel.ForAddress("http://localhost:15002", new GrpcChannelOptions())
Await channel.ConnectAsync()
Dim client = new SparkConnectService.SparkConnectServiceClient(channel)
Dim rangeRelation = new Relation()
rangeRelation.Range = New Spark.Connect.Range()
rangeRelation.Range.Start = 10
rangeRelation.Range.End = 100
rangeRelation.Range.Step = 5
rangeRelation.Range.NumPartitions = 1
Dim plan = new Plan()
plan.Command = New Command()
plan.Command.WriteOperation = New WriteOperation()
plan.Command.WriteOperation.Mode = WriteOperation.Types.SaveMode.Overwrite
plan.Command.WriteOperation.Source = "csv"
plan.Command.WriteOperation.Path = "/tmp/wowVB.csv"
plan.Command.WriteOperation.Input = rangeRelation
Dim request = new ExecutePlanRequest()
request.Plan = plan
Dim response = client.ExecutePlan(request, New Metadata())
While Await response.ResponseStream.MoveNext()
End While
Return True
End Function
End Module
and the output from this:
ls /tmp/wowVB.csv
_SUCCESS part-00000-3759aef3-88b2-4c7e-8123-243c0846d0ba-c000.csv

Conclusion
The point is that we can use the gRPC protocol to connect to Spark from any language. I chose C# and VB.NET, but nothing stops us from creating Spark jobs from any language capable of sending and receiving gRPC messages.
There is quite a bit of work in the Golang Spark project, and I used it extensively to get up and running. It has been a few years since I have actively developed in Golang, but it is very readable. (Odd bit of trivia: I created my GitHub account to submit a PR to an IDE for GOLang, and so that is why the GOEddie GitHub alias)
I am sure that we will soon see Spark applications written in Rust as well.
What is next?
I think if anyone is going to use this, then there are probably two personas; the first is a .NET developer who has no idea what the hell spark is and has some instructions to run a spark job - for them, this is all they need, they can create a plan and execute it.
The second, a probably more typical case, is people who want to use Spark and are familiar with the DataFrame API. For them, we need to provide a wrapper around the spark-connect API. I have had a play around, and it looks easy, so I’ll explore this more in future posts.
Additionally, we need to demonstrate this from Databricks, where people will probably want to use Spark and see Spark jobs running.
The stated goal of Spark Connect was to allow access from other languages, so let’s grab our .NET IDE and get on with it!