
Implementing functions and more fun in Spark Connect using gRPC and .NET
Goal of this post
The goal of this post is to look at creating a SparkSession and a DataFrame that will wrap the Range relation and then we will use the WithColumn function to add a column to the DataFrame and then we will use the Show function to show the DataFrame.
We won’t have a builder but we are moving towards:
var spark = SparkSession
.Builder
.Remote("http://localhost:15002")
.GetOrCreate();
var dataFrame = spark.Range(1000);
dataFrame.Show();
var dataFrame2 = dataFrame
.WithColumn("Hello",
Lit("Hello From Spark, via Spark Connect"));
I’m pretty much going to leave the code as-is from the previous post but will move things about a bit and add a SparkSession and a DataFrame class. Also, instead of passing the session id and client around i’m going to wrap them in the SparkSession so that we can just pass a single object and also use it to construct the DataFrame so we don’t even have to worry about passing it around.
The first thing is to take all of that gRPC connection stuff and shove in into SparkSession so it is hidden from the callers:
public SparkSession()
{
Headers = new Metadata(); //cluster id and auth header if using Databricks
var channel = GrpcChannel.ForAddress(GetSparkRemote(defaultRemote: "http://127.0.0.1:15002"), new GrpcChannelOptions());
channel
.ConnectAsync()
.Wait();
Client = new SparkConnectService.SparkConnectServiceClient(channel);
SessionId = Guid.NewGuid().ToString();
}
We should also start respecting the env variable SPARK_REMOTE:
private static string GetSparkRemote(string defaultRemote)
{
var sparkRemote = Environment.GetEnvironmentVariable("SPARK_REMOTE");
if (string.IsNullOrEmpty(sparkRemote))
{
return defaultRemote;
}
return sparkRemote.Replace("sc://", "http://");
}
The replace sc:// thing is one of the only requirements for consumers of the gRPC API (https://github.com/apache/spark/blob/master/connector/connect/docs/client-connection-string.md):
The URI scheme is fixed and set to sc:// but obviously gRPC doesn’t know about sc:// so flip to http:// - if it is calling databricks it will need to be https://.
This now gives us SparkSession` which creates the gRPC channel, client, and Spark session id. We will need to get it to do something:
public DataFrame Range(long end, long start = 0, long step = 1, int numPartitions = 1)
{
var relation = new Relation()
{
Common = new RelationCommon()
{
PlanId = PlanIdCache.GetPlanId(SessionId)
},
Range = new Spark.Connect.Range()
{
Start = start,
Step = step,
End = end,
NumPartitions = numPartitions
},
};
return new DataFrame(relation, this);
}
Now, instead of returning a Relation we are returning a DataFrame, which looks something like:
public class DataFrame
{
public Relation Relation { get; init; }
public SparkSession Session { get; init; }
public DataFrame(Relation relation, SparkSession session)
{
Relation = relation;
Session = session;
}
}
Now we can call spark.Range(1000) and get a DataFrame back:
var spark = new SparkSession();
var dataFrame = spark.Range(100);
Nice. Let’s start adding some methods to DataFrame, WithColumn seems like a good place to start:
public DataFrame WithColumn( string columnName, Expression value)
{
return new DataFrame(this.Relation.WithColumn(columnName, value), this.Session);
}
(see I said I was just going to call the code we had already written, it is fine for now).
Now WithColumn takes a name of a column and also an expression, so it is now time to start to build the Functions (think pyspark.sql.functions).
The requirements for Functions in my mind are:
- I don’t want to end up with one massive cs file, I want to split it up.
- I don’t want to have to write
Functions.Litetc (although I can if I want to) so I must be able to do anusing staticto get the methods.
What I settled on for now is to use a partial class called SparkConnect.Sql.Functions with a class for every group of functions like having a file for all of the Lit variants. Not totally sure on the grouping yet but am sure will be clear moving forward.
I did consider having a class for each group like LitFunctions then getting Functions to inherit but the using static bit breaks unless you do using static on the class that actually implements the methods or you do a new Lit inside the Functions class which I didn’t like.
Request Proxy
I would describe myself as a bit of a networking guy, when trying to understand the protocol I like to see the actual messages sent between the client (pyspark shell) and the Spark Connect server and there isn’t really anything satisfactory for this at the moment. You can take a network trace but the raw gRCP messages aren’t ideal and I found a couple of tools to decode gRPC but nothing was really what I wanted so I put together a super simple proxy that dumps out the contents of the requests and the responses:
https://github.com/GoEddie/spark-connect-blogs/tree/main/shared/SparkLoggingProxy
If you run this, it will list on a port, change your SPARK_REMOTE to this address this is listening on and it will dump out the contents of the requests:
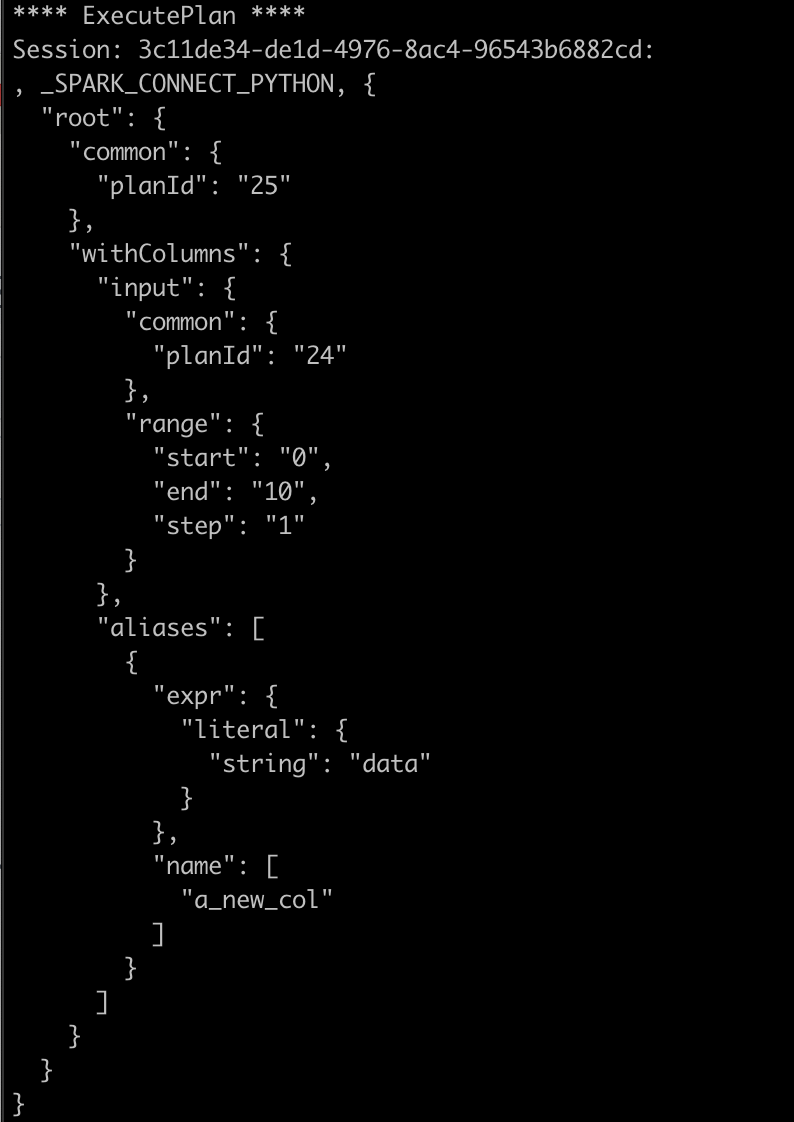
The proxy is super simple, just acts as a gRPC server using ASP.NET, prints out the request, then forwards the call onto the real gRPC server:
public override async Task ExecutePlan(ExecutePlanRequest request, IServerStreamWriter<ExecutePlanResponse> responseStream, ServerCallContext context)
{
Console.WriteLine("**** ExecutePlan ****");
Console.WriteLine(string.IsNullOrEmpty(request.OperationId)
? $"Session: {request.SessionId}:"
: $"Session: {request.SessionId}, OperationId: {request.OperationId}:");
Console.WriteLine(request.PrettyPrint());
var response = _client.ExecutePlan(request, context.RequestHeaders);
while (await response.ResponseStream.MoveNext())
{
await responseStream.WriteAsync(response.ResponseStream.Current);
}
}
If you don’t want to proxy the requests and look at them in detail then the Spark UI does do a pretty good job of showing the plan that is received via spark Connect but I wanted something a little bit more, hence the proxy.
Plan Id
Using the proxy I was able to connect the pyspark shell via my proxy because I wanted to see if the plan it was generating was the same plan as I was generating and I noticed two things.
Firstly, to use Lit to create an Array type, instead of using the Array gRPC property you need to call a function called array:
"aliases": [
{
"expr": {
"unresolvedFunction": {
"functionName": "array",
"arguments": [
{
"literal": {
"string": "abc"
}
},
{
"literal": {
"string": "def"
}
}
]
}
},
"name": [
"array_col"
]
}
]
Secondly, every time you run a command in the pyspark shell like Show or Collect the shell sends the plan to the server and there is a property called common with a planId that increments each time the plan is sent. Note, there doesn’t seem to be any sort of local caching but that seems fairly trivial to implement I think?
I’ve added a way to get an incrementing plan id from the session and now my plans are matching the pyspark ones a bit better:
{
"root": {
"common": {
"planId": "2"
},
"showString": {
"input": {
"withColumns": {
"input": {
"withColumns": {
"input": {
"withColumns": {
"input": {
"common": {
"planId": "1"
},
"range": {
"start": "95",
"end": "100",
"step": "1",
"numPartitions": 1
}
},
"aliases": [
{
"expr": {
"unresolvedFunction": {
"functionName": "array",
"arguments": [
{
"literal": {
"string": "Hello"
}
},
{
"literal": {
"string": "There"
}
}
]
}
},
"name": [
"array_values_in_col"
]
}
]
}
},
"aliases": [
{
"expr": {
"literal": {
"integer": 18
}
},
"name": [
"binary_col"
]
}
]
}
},
"aliases": [
{
"expr": {
"literal": {
"decimal": {
"value": "1235400.000000000062527760747",
"precision": 28,
"scale": 22
}
}
},
"name": [
"decimal_col"
]
}
]
}
},
"numRows": 20,
"truncate": 100
}
}
}
So with the new SparkSession, DataFrame, and Function classes we can now do this:
using SparkConnect;
using static SparkConnect.Sql.Functions;
var spark = new SparkSession();
var dataFrame =
spark.Range(100, 95)
.WithColumn("array_values_in_col", Lit(new List<string>() { "Hello", "There" }))
.WithColumn("binary_col", Lit(0x12))
.WithColumn("decimal_col", Lit(1235400.000000000062527760747M));
Console.WriteLine("**** Show ****");
dataFrame.Show(20, 100);
which outputs:
+---+-------------------+----------+-----------------------------+
| id|array_values_in_col|binary_col| decimal_col|
+---+-------------------+----------+-----------------------------+
| 95| [Hello, There]| 18|1235400.000000000062527760747|
| 96| [Hello, There]| 18|1235400.000000000062527760747|
| 97| [Hello, There]| 18|1235400.000000000062527760747|
| 98| [Hello, There]| 18|1235400.000000000062527760747|
| 99| [Hello, There]| 18|1235400.000000000062527760747|
+---+-------------------+----------+-----------------------------+
Perfect.