
Spark Connect Dotnet November 2024 Where are we?
Introduction
There have been quite a few changes in the last couple of months and I just wanted to give a quick update on the current state of the project. In terms of usage I am starting to hear from people using the library and submitting pr’s and requests so although usage is pretty low (which is expected from the fact that the Microsoft supported version usage wasn’t very high) it is growing which is interesting.
Production Ready?
I would say yes, but when you decide where and how you will use spark connect dotnet there are two factors, the first is that this uses the officially supported Spark Connect API and so if you were ever to be in the situation that you needed support from a vendor then the worst case scenario is that you would be asked to reproduce the issue in python and translating from .NET to Python is going to be pretty straightforward, although I would hope that being able to view the logical plan and working with that would be enough to debug a production issue. Whether a plan was generated in .NET, Python, Scala, Go, or manually written in notepad it would make no difference to how the plan is executed on Spark.
The second point to consider is that if the library has a bug in the way a plan is generated then the gRPC client is always available so you can generate your own plan and send that down the gRPC channel, so it will take a bit more work but without requiring me to do anything you can fix your own issue.
Spark 4
The most recent version of the library now supports the new Spark 4.0 types such as the Variant type and also the new functions such as try_to_*.
Reattach Execute
When implementing the new functions for Spark 4.0 I also rewrote the way that requests were sent to Spark and responses were parsed. The previous version worked well locally or on a local network but didn’t deal very well when connecting to Databricks, especially on Azure if we had a long running connection that was idle while the response was being generated the connection could be killed. To handle this Spark Connect has the concept of a ReattachExecute where you save the response id and can use that to re-connect a killed tcp session to keep the Spark Session active and to receive the whole response.
While writing this I have also included a build for checking that the tests can connect to databricks, start a cluster, run on a Databricks cluster including a long running request that is idle for 10 minutes and I will be running this on every release as well as running the unit tests which check that each function runs and executes.
Spark ML
There is currently a PR open to add support for Spark ML to Spark Connect, when this is merged then we can use the Spark Connect API to implement the Spark ML interface. There is something interesting here though because the way PySpark implements Spark ML is that the models are built using Spark but some of the functions like calling dot on a DenseVector are handed off to numpy and so some of the functions will not be available via the Spark Connect API.
I am not sure which way to go with this, I could implement the functions in .NET, they are well documented so it is doable but also there are a couple of .NET libraries that make numpy available in .NET so it might be better to re-use those functions. If I end up using a third party library for the numpy functions then I will likely make Spark.Connect.Dotnet.ML a separate library so it is only if you want to use it that you will need to include the extra libraries.
Stats
Pull Requests
22 Pull requests, 21 by me https://github.com/GoEddie/spark-connect-dotnet/pulls
Releases
15 Releases: https://github.com/GoEddie/spark-connect-dotnet/releases
NuGet
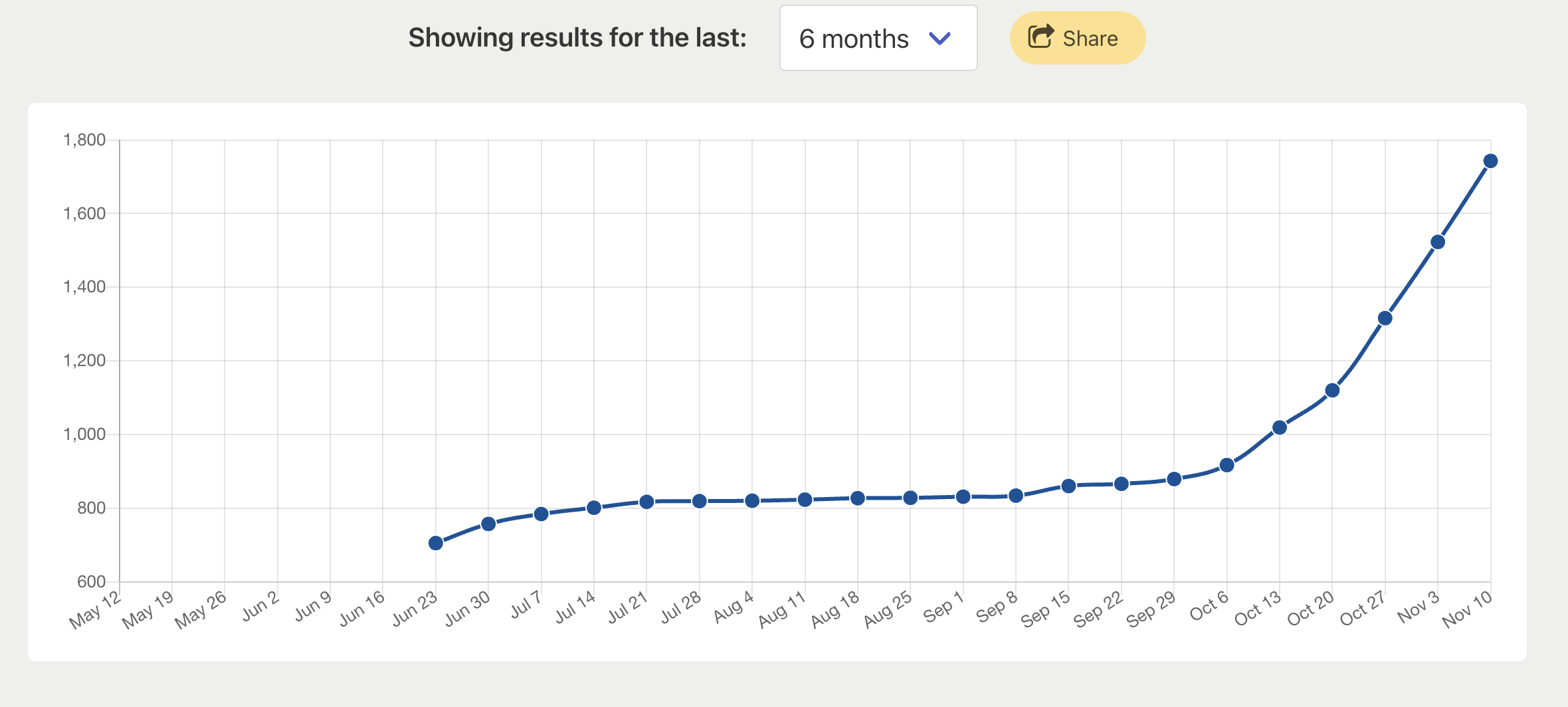
Future plans
Not satisfied with StringOrCol
In the PySpark implementation we have StringOrCol which means you can pass either a string which is a column name or you can pass a col and at runtime PySpark works out what you have passed in. Now, .NET doesn’t have union types and I can’t find a satisfactory way to implement a function that can take either a String or a Col so I have provided string versions and col versions but you can’t mix and match.
I would like to revisit this and come up with a nice way to work with both types but so far I haven’t been able to come up with something that works well.
Split DataFrame API into separate project
I am super keen on highlighting the fact that people are free to use the DataFrame API that I have created which mirrors the PySpark API as much as possible but there is nothing stopping them, and I would actively encourage people to create their own plans so that if there is a situation where my library doesn’t do what you want you are able to work around the issue. I never want to be in the situation that the Microsoft Spark dotnet got in where if something didn’t work you were totally stuck.
To help with this I am considering pulling out the core gRPC operations that send plans up and down and splitting from the DataFrame API part of the code which is responsible for building the logical plans. In an ideal world you would be able to either supply your own DataFrame API or your own gRPC operations and pick and choose what you implement yourself and what is provided for you.
Tests don’t validate the responses
When I wrote this I autogenerated the bulk of the functions and while creating those I also autogenerated a test for each function but the tests call the function and do not validate the response. I am in two minds about whether this is perfect or I should be validating the response. It isn’t the aim of this library to ensure that Spark works correctly merely to ensure that when you ask for x you get x and the tests work for that.
Function Metadata
One longer term goal is to create a set of metadata from the Spark source that allows me to generate functions, tests, and documentation. I would love to be in the position that I can generate a complete DataFrame API from metadata so we could have a version of the library that matches the PySpark API including the naming so you could copy and paste from PySpark and have the code pretty much work, also a Scala version and a .NET version - all re-creatable with doc comments and tests.
I have tried a couple of times and, like the StringOrCol union types haven’t been able to get exactly what I want but it is something I will keep working on. Hopefully, until the next major Apache Spark release there won’t be that much work needed on the library so I can work on some of the longer term plans.